20 Powder OpenStack Tutorial
This tutorial will walk you through the process of creating a small cloud on Powder using OpenStack. Your copy of OpenStack will run on bare-metal machines that are dedicated for your use for the duration of your experiment. You will have complete administrative access to these machines, meaning that you have full ability to customize and/or configure your installation of OpenStack. Powder provides access to cloud resources through CloudLab, and some screenshots in this tutorial have the CloudLab name and logo in them. When you use Powder through https://www.powderwireless.net, you will see the Powder name and logo instead.
20.1 Objectives
In the process of taking this tutorial, you will learn to:
Log in to Powder
Create your own cloud by using a pre-defined profile
Access resources in a cloud that you create
Use administrative access to customize your cloud
Clean up your cloud when finished
Learn where to get more information
20.2 Prerequisites
This tutorial assumes that you have an existing account on Powder. Instructions for getting an account can be found here.
20.3 Logging In
If you have signed up for an account at the Powder website, simply open https://www.powderwireless.net/ in your browser, click the “Log In” button, enter your username and password.
20.4 Building Your Own OpenStack Cloud
Once you have logged in to Powder, you will “instantiate” a “profile” to create an experiment. (An experiment in Powder is similar to a “slice” in GENI.) Profiles are Powder’s way of packaging up configurations and experiments so that they can be shared with others. Each experiment is separate: the experiment that you create for this tutorial will be an instance of a profile provided by the facility, but running on resources that are dedicated to you, which you have complete control over. This profile uses local disk space on the nodes, so anything you store there will be lost when the experiment terminates.
The OpenStack cloud we will build in this tutorial is very small, but Powder has additional hardware that can be used for larger-scale experiments.
For this tutorial, we will use a basic profile that brings up a small OpenStack cloud. The Powder staff have built this profile by capturing disk images of a partially-completed OpenStack installation and scripting the remainder of the install (customizing it for the specific machines that will get allocated, the user that created it, etc.) See this manual’s section on profiles for more information about how they work.
- Start Experiment
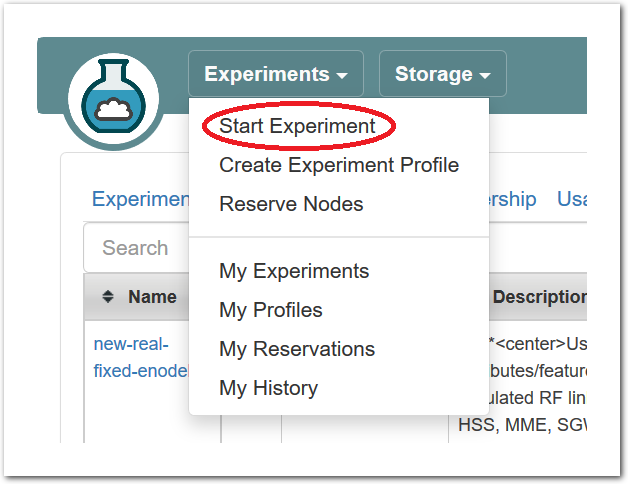 After logging in, you are taken to your main status dashboard. Select “Start Experiment” from the “Experiments” menu.
After logging in, you are taken to your main status dashboard. Select “Start Experiment” from the “Experiments” menu. - Select a profile
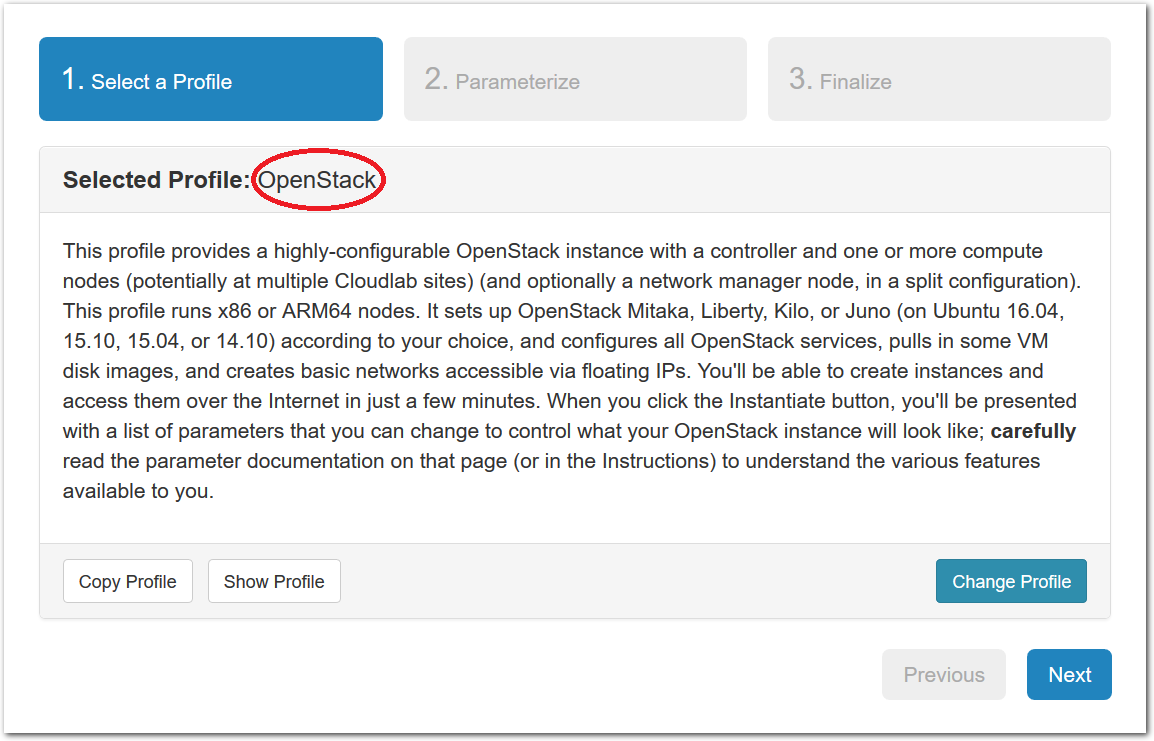 The “Start an Experiment” page is where you will select a profile to instantiate. We will use the OpenStack profile; if it is not selected, follow this link or click the “Change Profile” button, and select “OpenStack” from the list on the left.Once you have the correct profile selected, click “Next”
The “Start an Experiment” page is where you will select a profile to instantiate. We will use the OpenStack profile; if it is not selected, follow this link or click the “Change Profile” button, and select “OpenStack” from the list on the left.Once you have the correct profile selected, click “Next”
- Set parametersProfiles in Powder can have parameters that affect how they are configured; for example, this profile has parameters that allow you to set the size of your cloud, spread it across multiple clusters, and turn on and off many OpenStack options.For this tutorial, we will leave all parameters at their defaults and just click “next”.
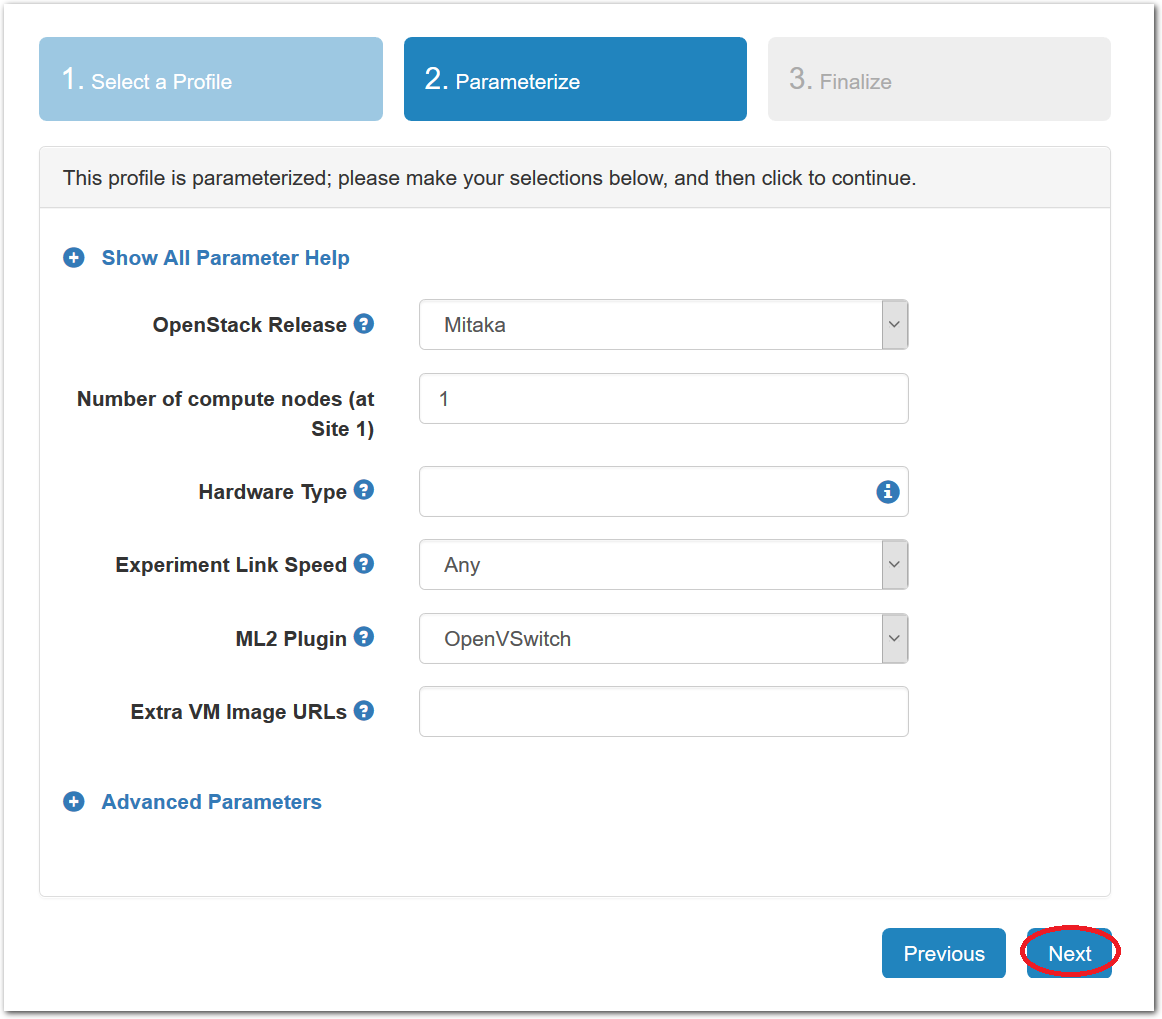
- Select a clusterPowder has multiple clusters available to it. Some profiles can run on any cluster, some can only run on specific ones due to specific hardware constraints, etc.Note: If you are at an in-person tutorial, the instructor will tell you which cluster to select. Otherwise, you may select any cluster.
The dropdown menu for the clusters shows you both the health (outer ring) and available resources (inner dot) of each cluster. The “Check Cluster Status” link opens a page (in a new tab) showing the current utilization of all Powder clusters.
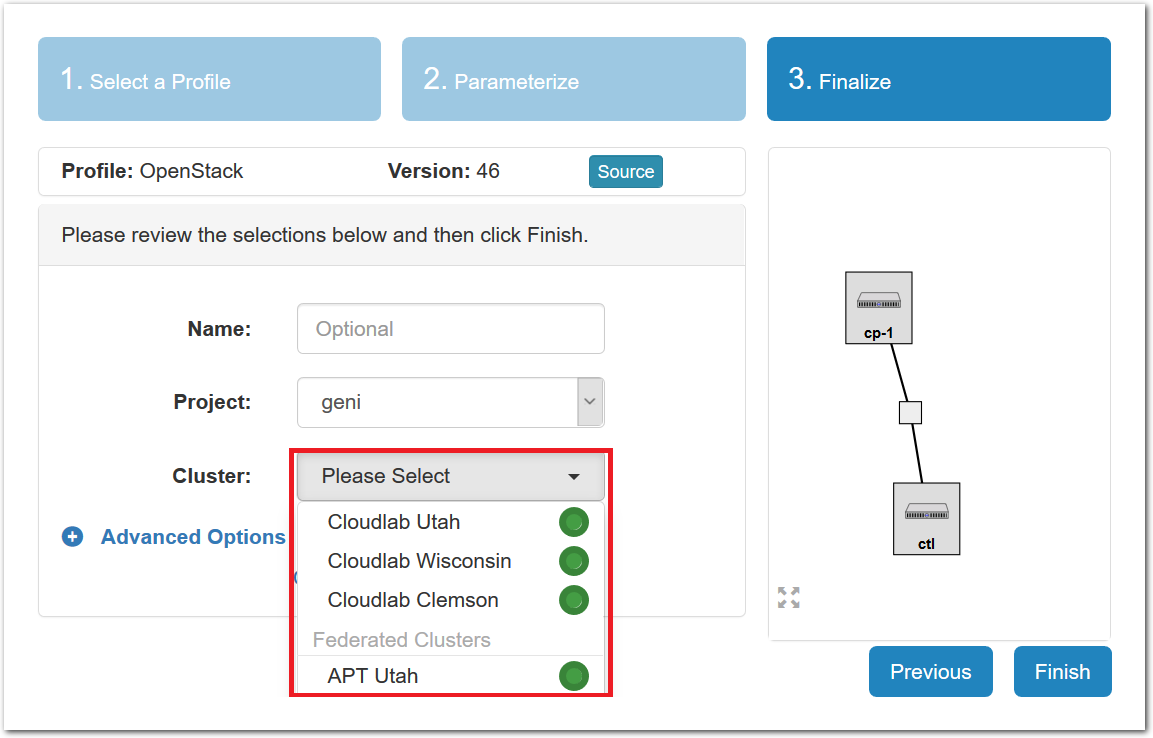
- Click Finish!When you click the “finish” button, Powder will start provisioning the resources that you requested on the cluster that you selected.
You may optionally give your experiment a name—
this can be useful if you have many experiments running at once. 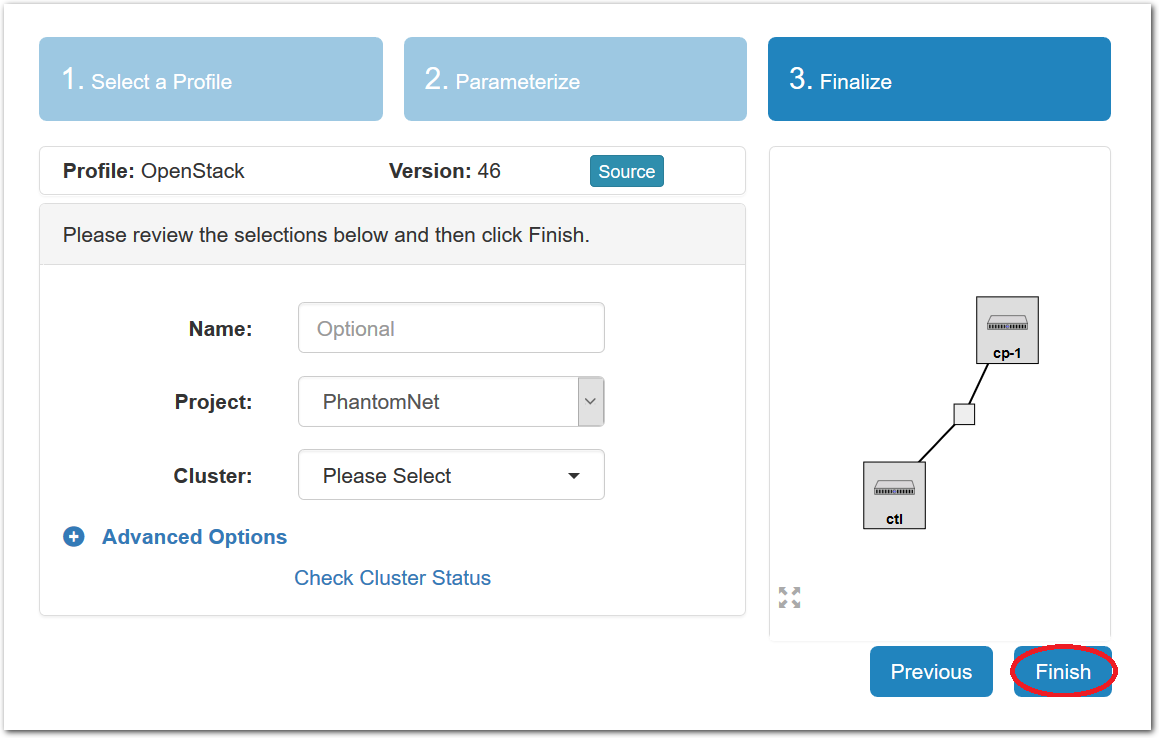
- Powder instantiates your profilePowder will take a few minutes to bring up your copy of OpenStack, as many things happen at this stage, including selecting suitable hardware, loading disk images on local storage, booting bare-metal machines, re-configuring the network topology, etc. While this is happening, you will see this status page:
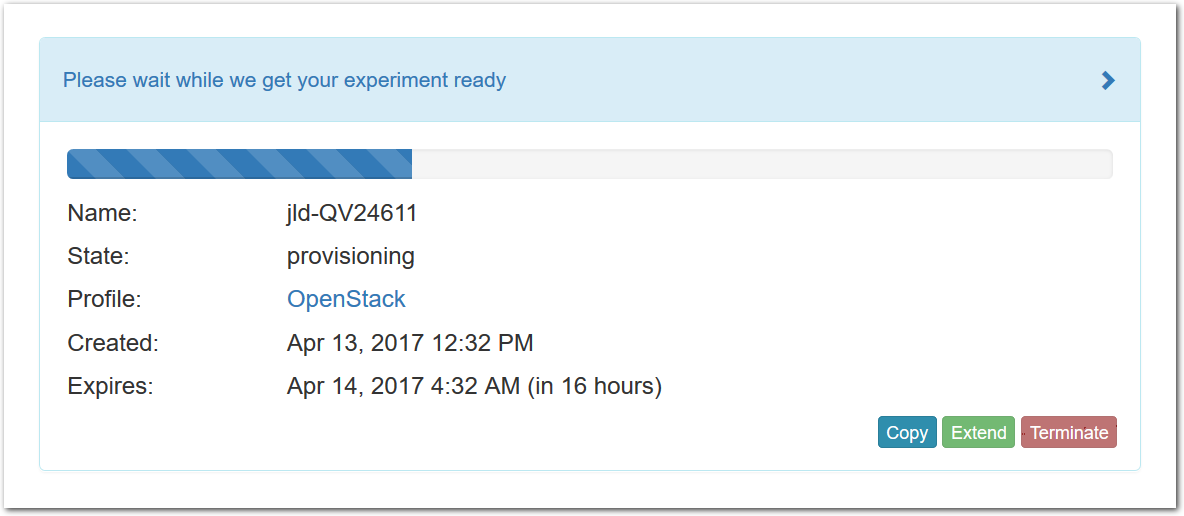
Provisioning is done using the GENI APIs; it is possible for advanced users to bypass the Powder portal and call these provisioning APIs from their own code. A good way to do this is to use the geni-lib library for Python.
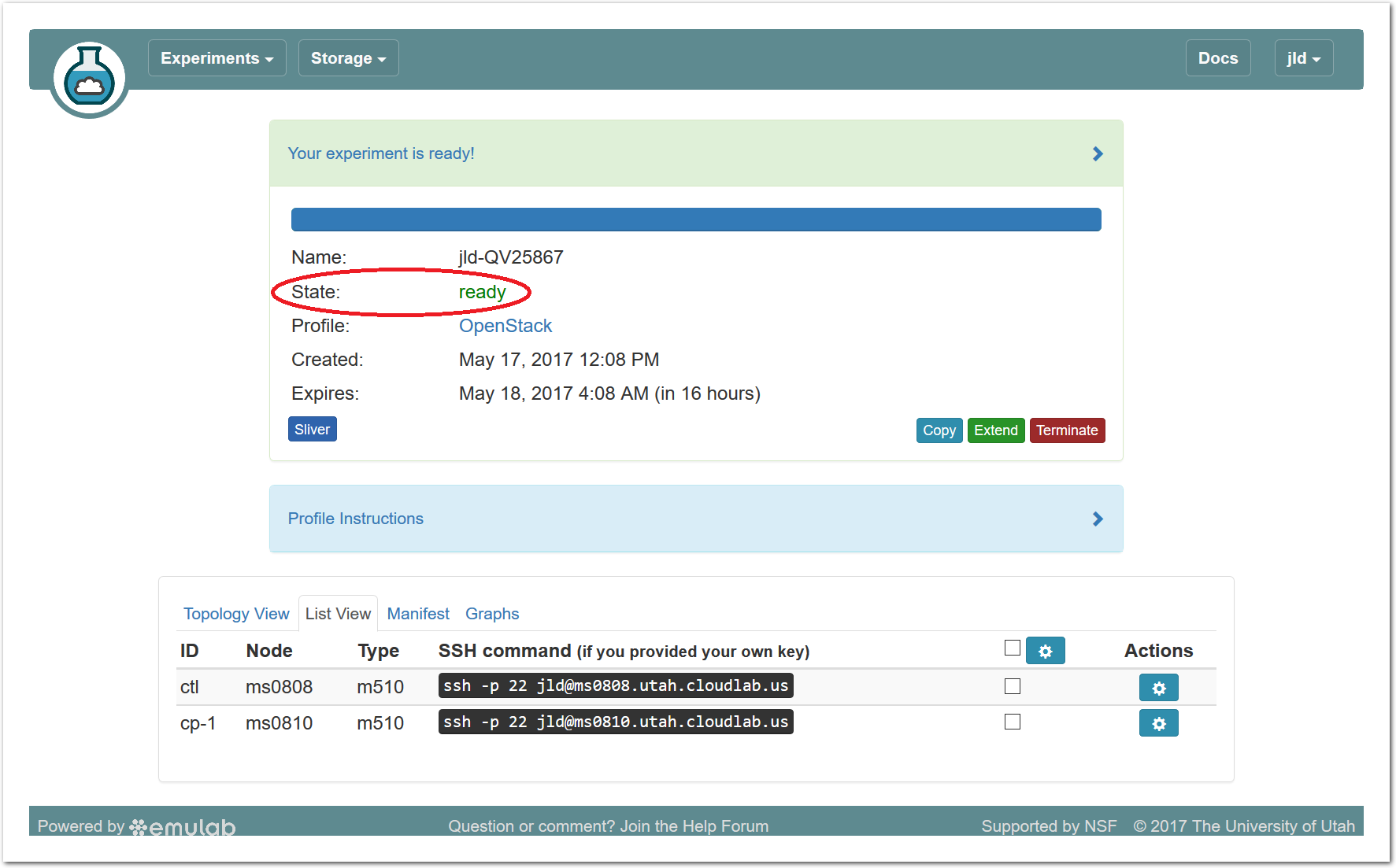
As soon as a set of resources have been assigned to you, you will see details about them at the bottom of the page (though you will not be able to log in until they have gone through the process of imaging and booting.) While you are waiting for your resources to become available, you may want to have a look at the Powder user manual, or use the “Sliver” button to watch the logs of the resources (“slivers”) being provisioned and booting. - Your cloud is ready!When the web interface reports the state as “Booted”, your cloud is provisioned, and you can proceed to the next section.Important: A “Booted” status indicates that resources are provisioned and booted; this particular profile runs scripts to complete the OpenStack setup, and it will be a few more minutes before OpenStack is fully ready to log in and create virtual machine instances. You will be able to tell that this has finished when the status changes from “Booted” to “Ready”. For now, don’t attempt to log in to OpenStack, we will explore the Powder experiment first.
20.5 Exploring Your Experiment
Now that your experiment is ready, take a few minutes to look at various parts of the Powder status page to help you understand what resources you’ve got and what you can do with them.
20.5.1 Experiment Status
The panel at the top of the page shows the status of your experiment—
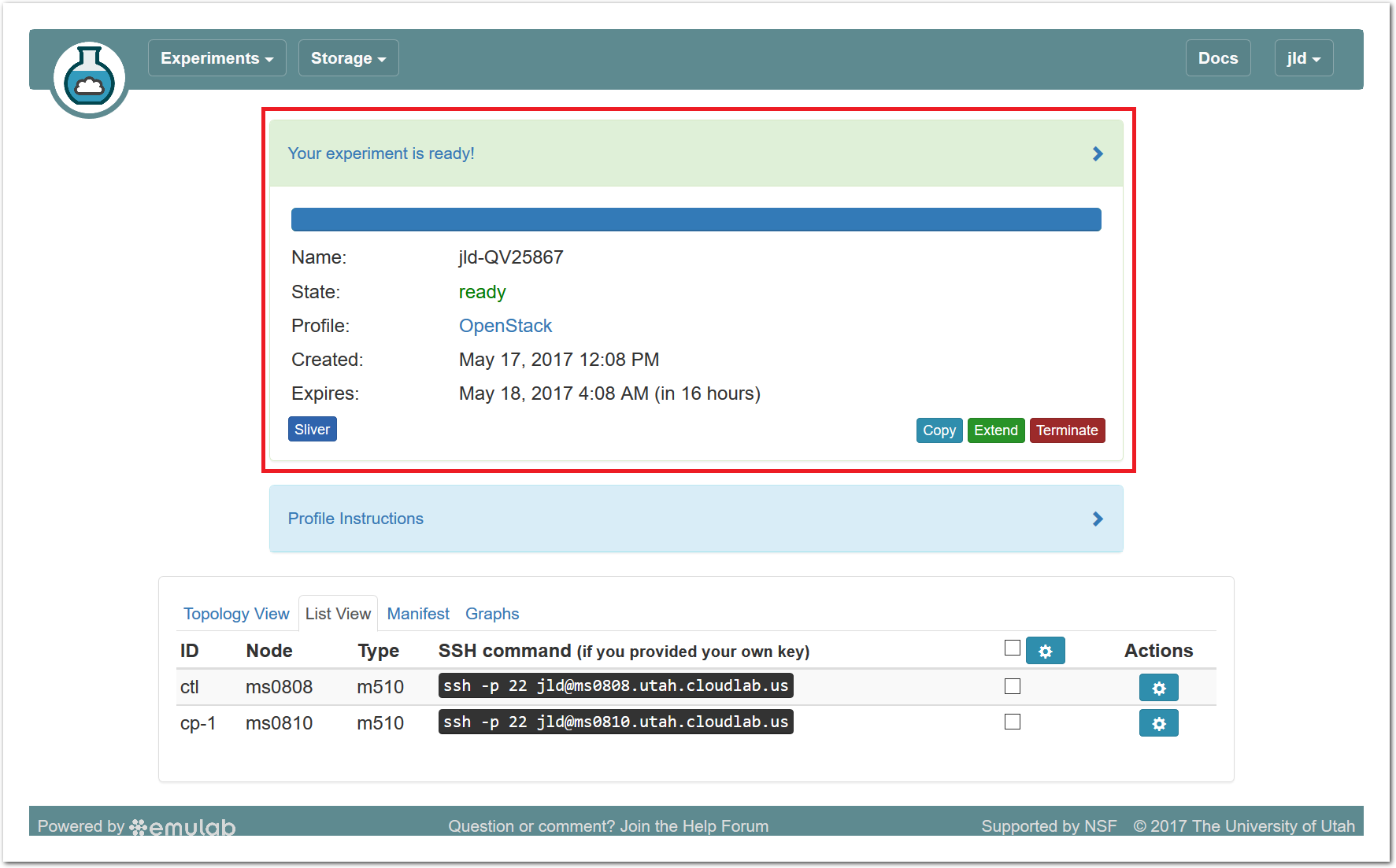
Note that the default lifetime for experiments on Powder is less than a day; after this time, the resources will be reclaimed and their disk contents will be lost. If you need to use them for longer, you can use the “Extend” button and provide a description of why they are needed. Longer extensions require higher levels of approval from Powder staff. You might also consider creating a profile of your own if you might need to run a customized environment multiple times or want to share it with others.
You can click the title of the panel to expand or collapse it.
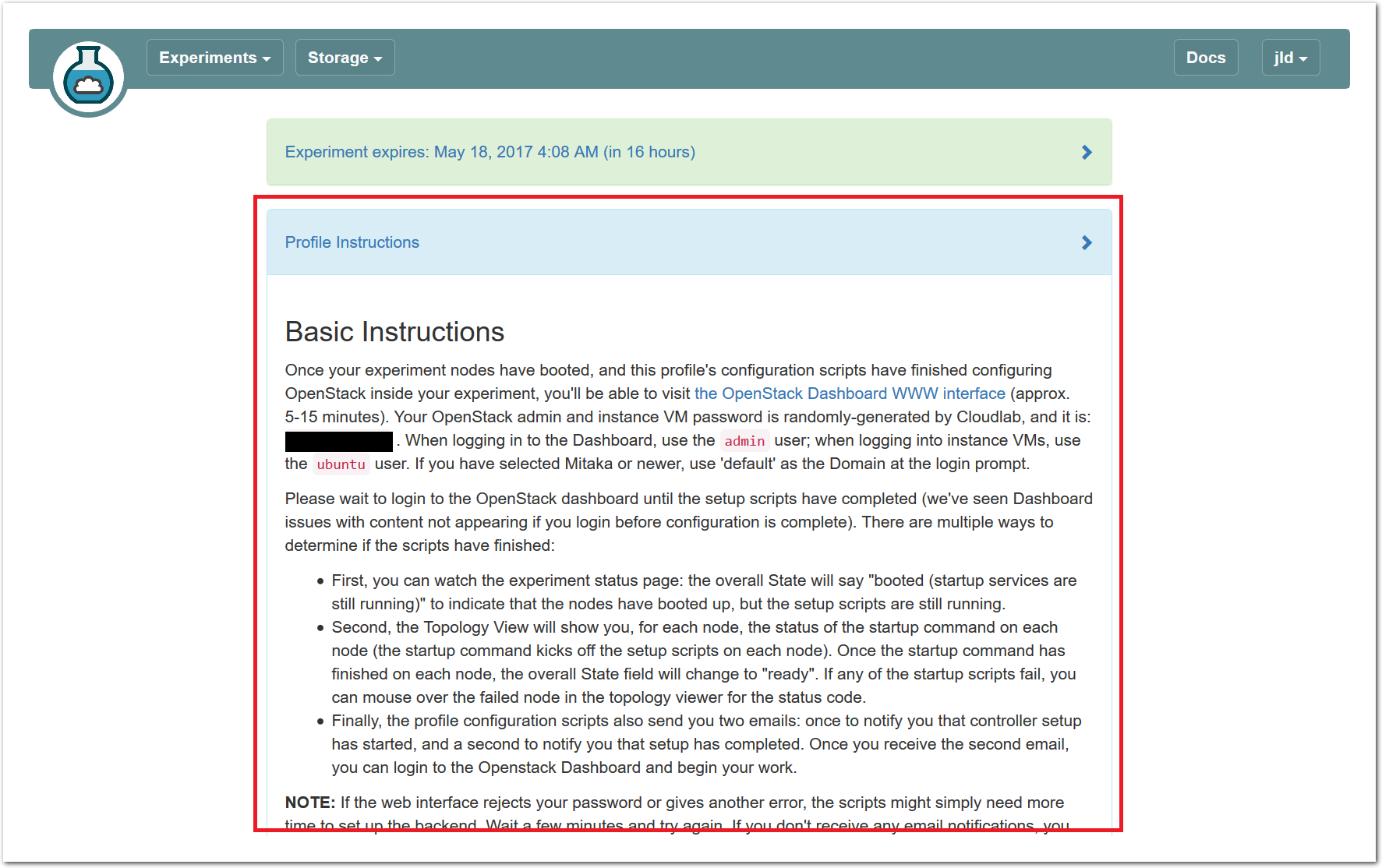
20.5.2 Profile Instructions
Profiles may contain written instructions for their use. Clicking on the title
of the “Profile Instructions” panel will expand (or collapse) it; in this
case, the instructions provide a link to the administrative interface of
OpenStack, and give you passwords to use to log in. (Don’t log into OpenStack
yet—
20.5.3 Topology View
At the bottom of the page, you can see the topology of your experiment. This profile has three nodes connected by a LAN, which is represented by a gray box in the middle of the topology. The names given for each node are the names assigned as part of the profile; this way, every time you instantiate a profile, you can refer to the nodes using the same names, regardless of which physical hardware was assigned to them. The green boxes around each node indicate that they are up; click the “Refresh Status” button to initiate a fresh check.
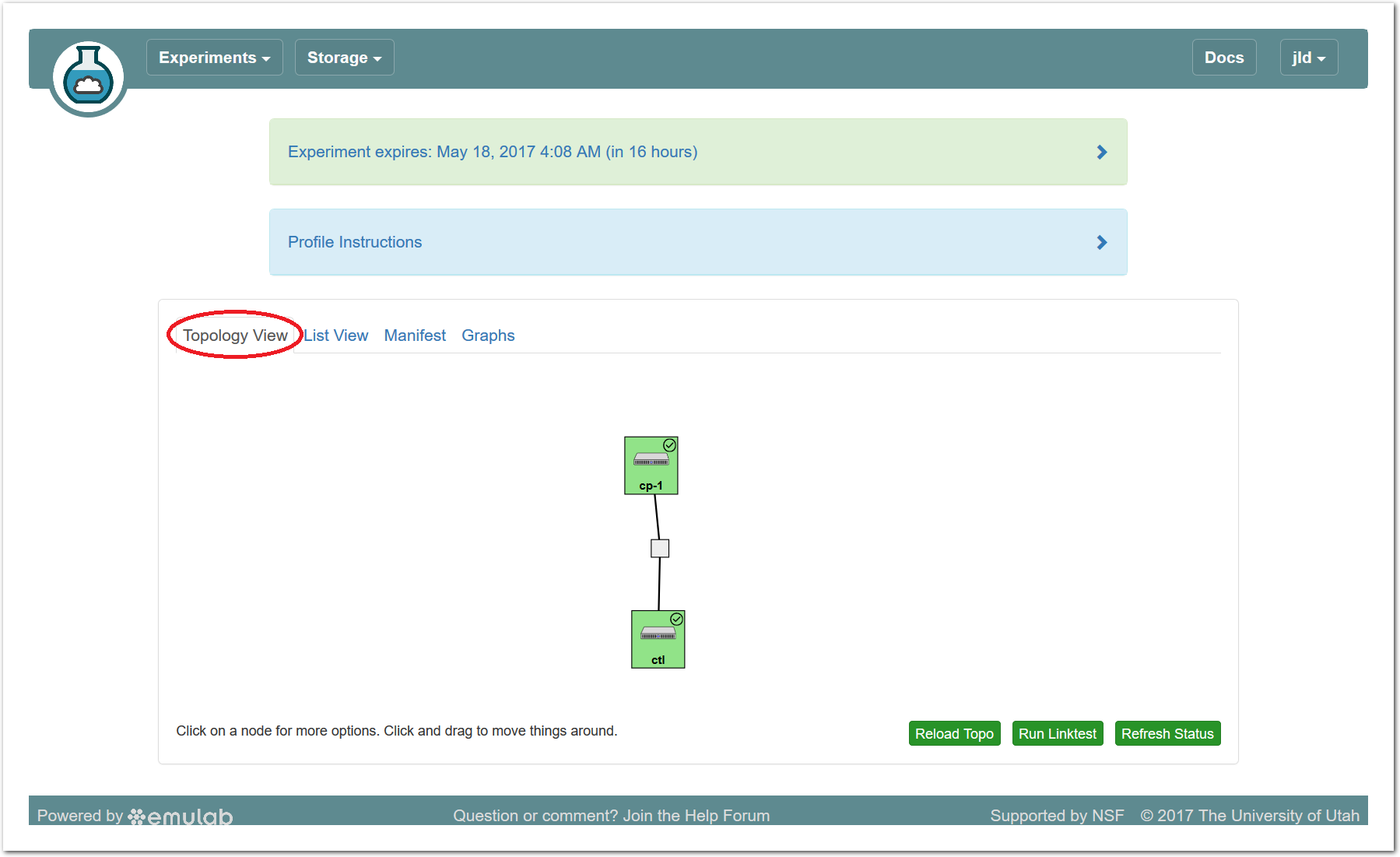
If an experiment has “startup services” (programs that run at the beginning of the experiment to set it up), their status is indicated by a small icon in the upper right corner of the node. You can mouse over this icon to see a description of the current status. In this profile, the startup services on the compute node(s) typically complete quickly, but the control node may take much longer.
It is important to note that every node in Powder has at least two network interfaces: one “control network” that carries public IP connectivity, and one “experiment network” that is isolated from the Internet and all other experiments. It is the experiment net that is shown in this topology view. You will use the control network to ssh into your nodes, interact with their web interfaces, etc. This separation gives you more freedom and control in the private experiment network, and sets up a clean environment for repeatable research.
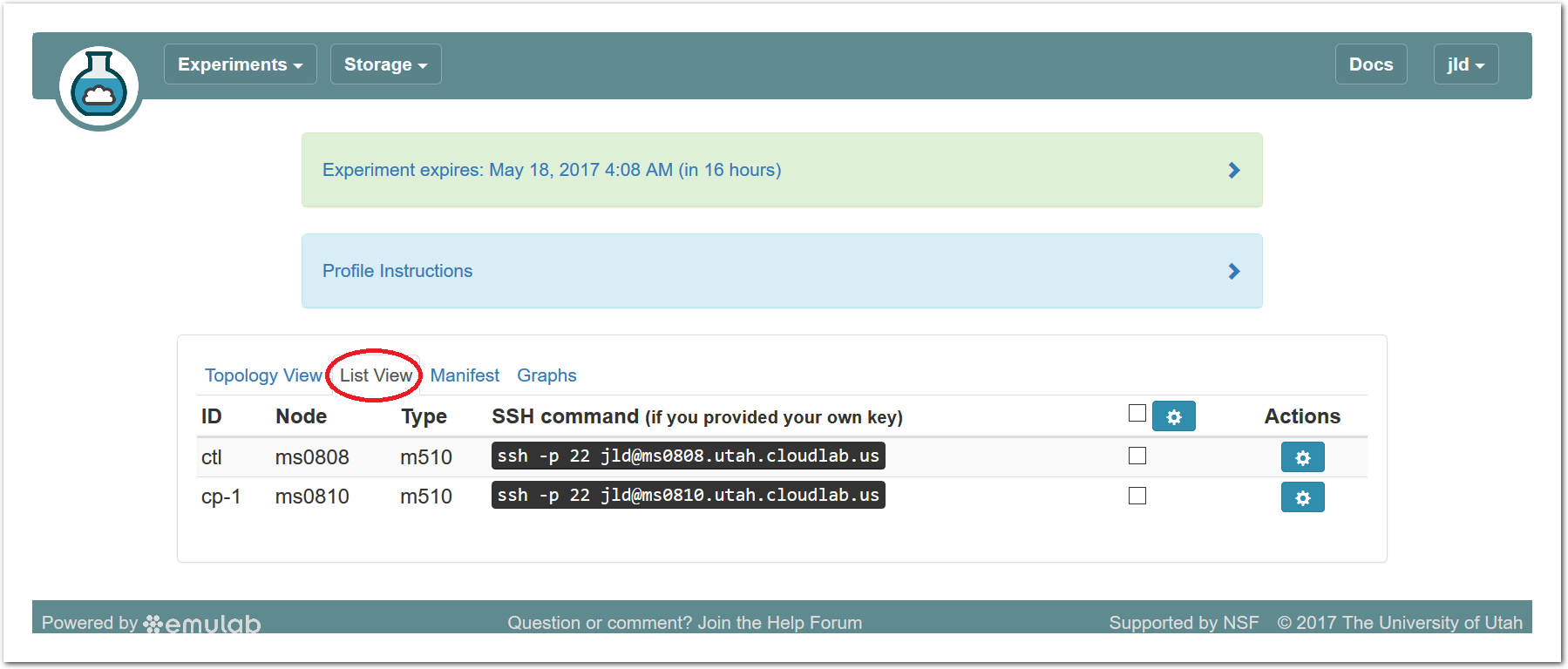
20.5.4 List View
The list view tab shows similar information to the topology view, but in a different format. It shows the identities of the nodes you have been assigned, and the full ssh command lines to connect to them. In some browsers (those that support the ssh:// URL scheme), you can click on the SSH commands to automatically open a new session. On others, you may need to cut and paste this command into a terminal window. Note that only public-key authentication is supported, and you must have set up an ssh keypair on your account before starting the experiment in order for authentication to work.
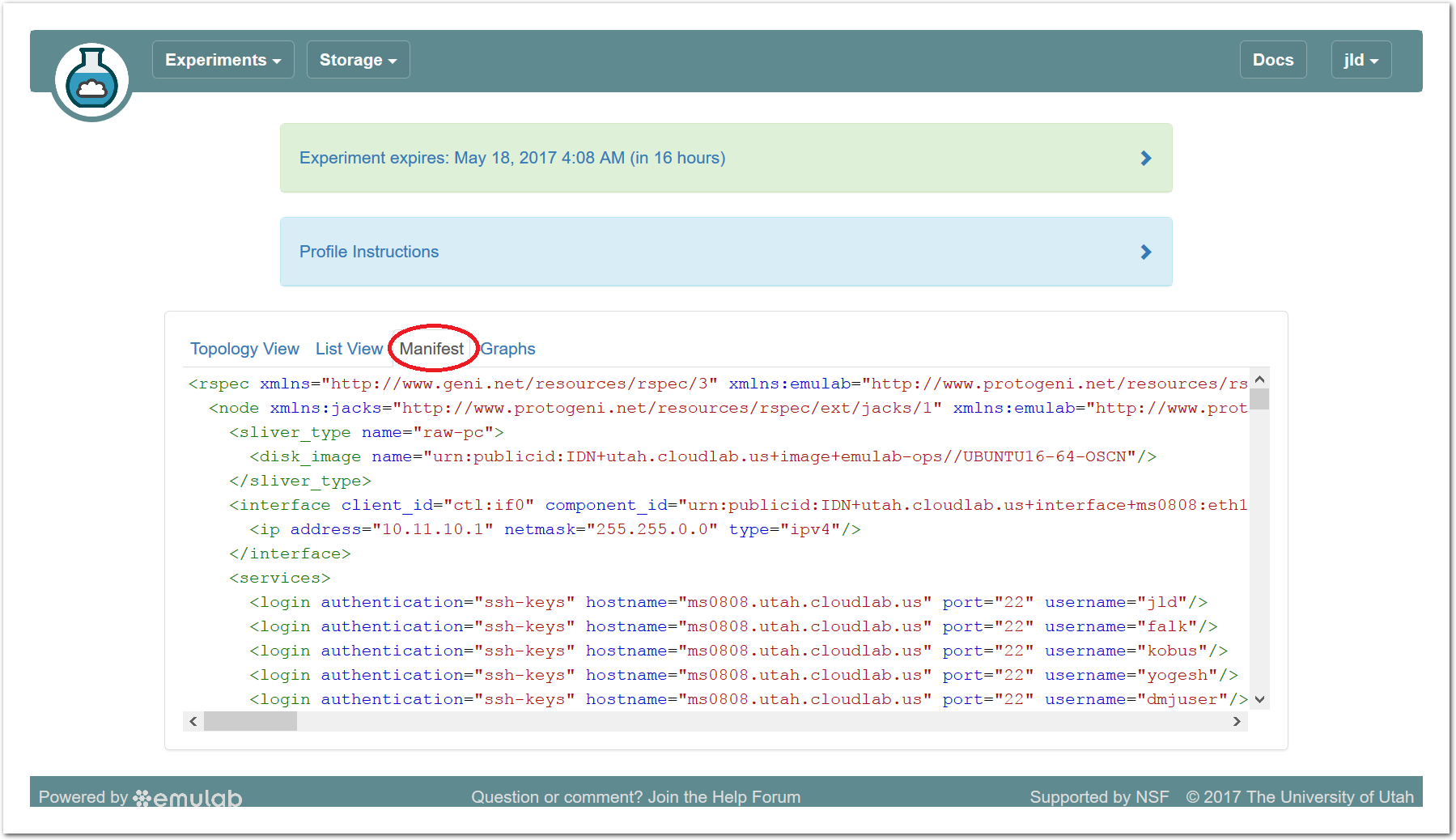
20.5.5 Manifest View
The third default tab shows a manifest detailing the hardware that has been assigned to you. This is the “request” RSpec that is used to define the profile, annotated with details of the hardware that was chosen to instantiate your request. This information is available on the nodes themselves using the geni-get command, enabling you to do rich scripting that is fully aware of both the requested topology and assigned resources.
Most of the information displayed on the Powder status page comes directly from this manifest; it is parsed and laid out in-browser.
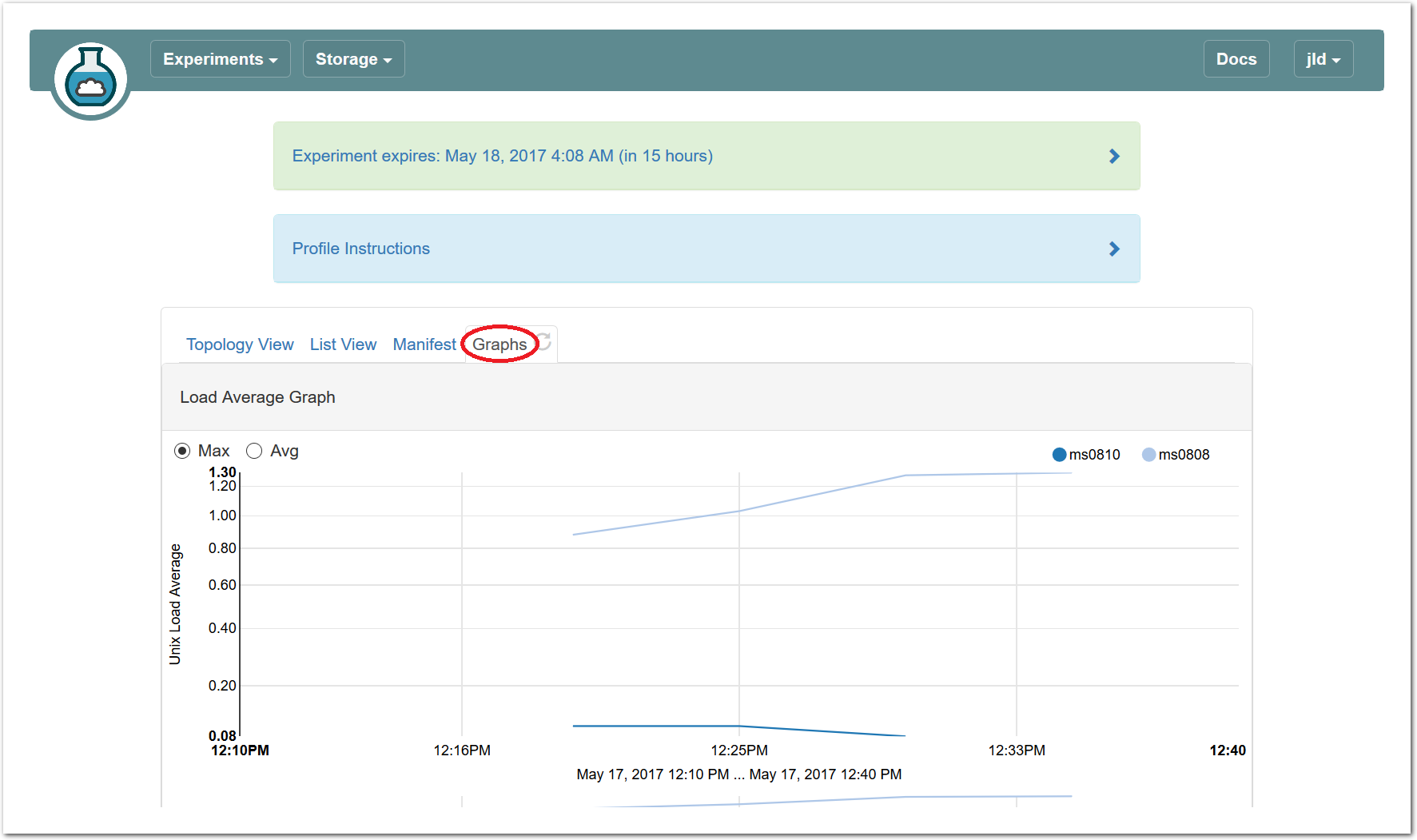
20.5.6 Graphs View
The final default tab shows a page of CPU load and network traffic graphs for the nodes in your experiment. On a freshly-created experiment, it may take several minutes for the first data to appear. After clicking on the “Graphs” tab the first time, a small reload icon will appear on the tab, which you can click to refresh the data and regenerate the graphs. For instance, here is the load average graph for an OpenStack experiment running this profile for over 6 hours. Scroll past this screenshot to see the control and experiment network traffic graphs. In your experiment, you’ll want to wait 20-30 minutes before expecting to see anything interesting.
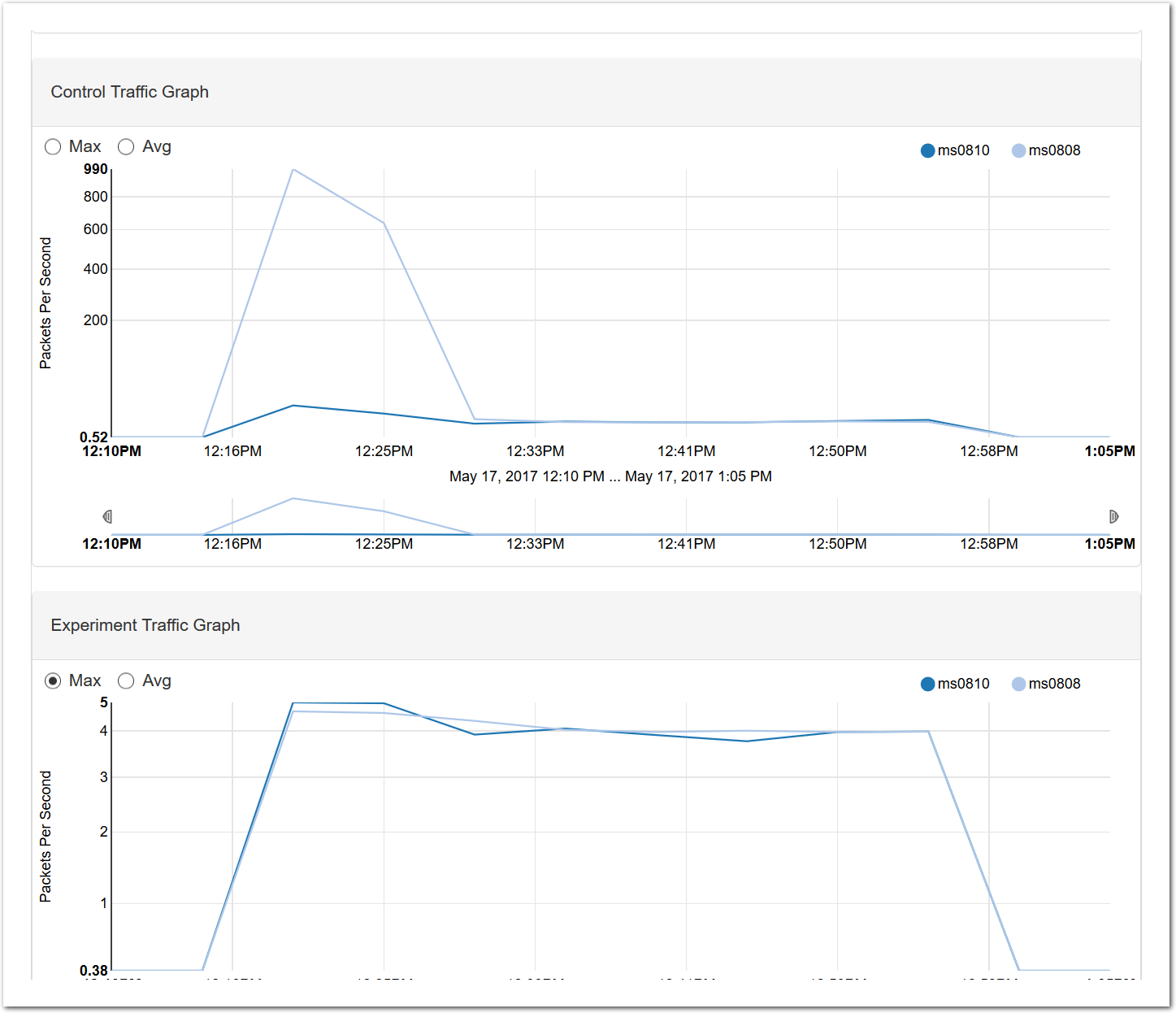
Here are the control network and experiment network packet graphs at the same time. The spikes at the beginning are produced by OpenStack setup and configuration, as well as the simple OpenStack tasks you’ll perform later in this profile, like adding a VM.
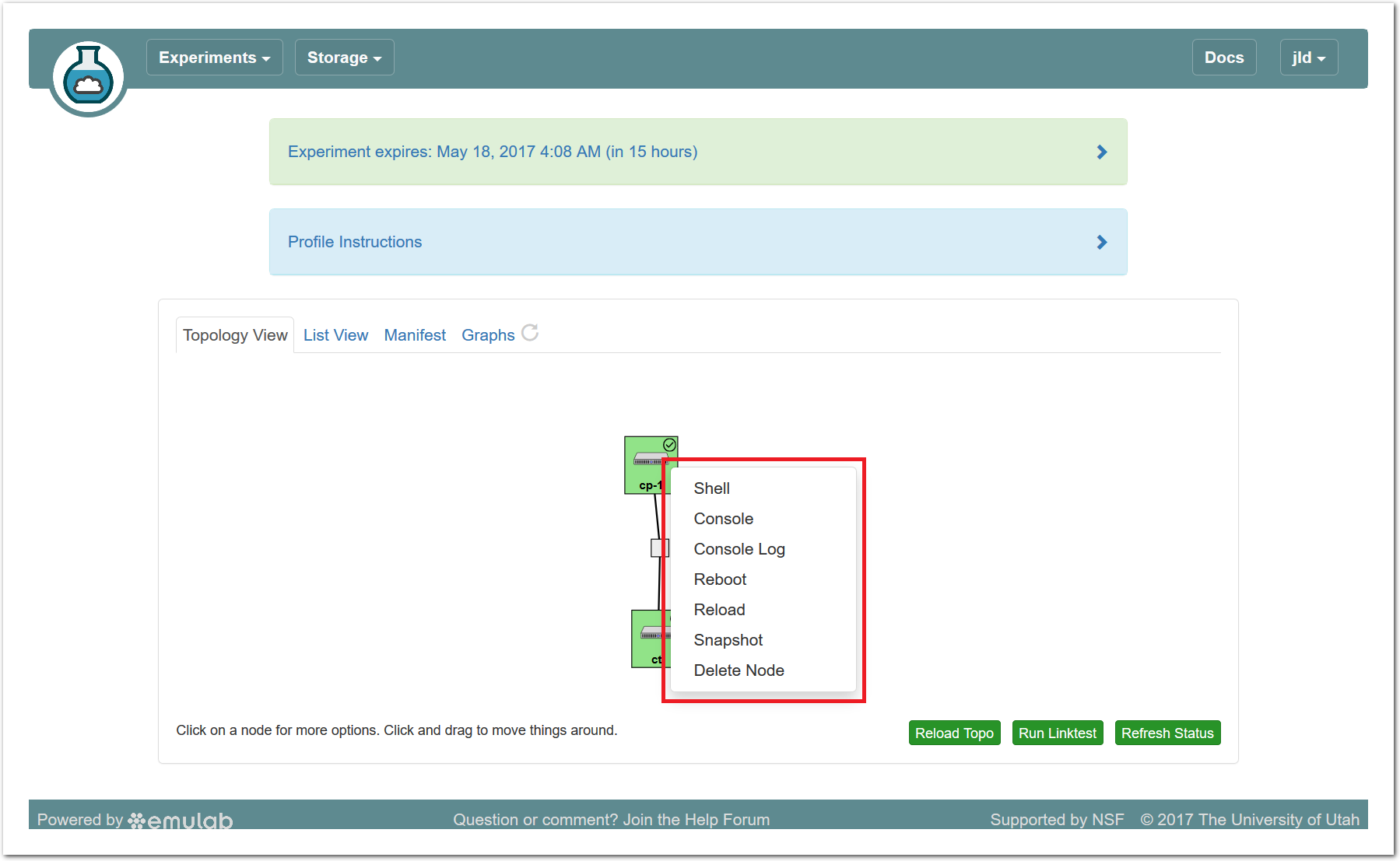
20.5.7 Actions
In both the topology and list views, you have access to several actions that you may take on individual nodes. In the topology view, click on the node to access this menu; in the list view, it is accessed through the icon in the “Actions” column. Available actions include rebooting (power cycling) a node, and re-loading it with a fresh copy of its disk image (destroying all data on the node). While nodes are in the process of rebooting or re-imaging, they will turn yellow in the topology view. When they have completed, they will become green again. The shell and console actions are described in more detail below.
20.5.8 Web-based Shell
Powder provides a browser-based shell for logging into your nodes, which is accessed through the action menu described above. While this shell is functional, it is most suited to light, quick tasks; if you are going to do serious work, on your nodes, we recommend using a standard terminal and ssh program.
This shell can be used even if you did not establish an ssh keypair with your account.
Two things of note:
Your browser may require you to click in the shell window before it gets focus.
Depending on your operating system and browser, cutting and pasting into the window may not work. If keyboard-based pasting does not work, try right-clicking to paste.
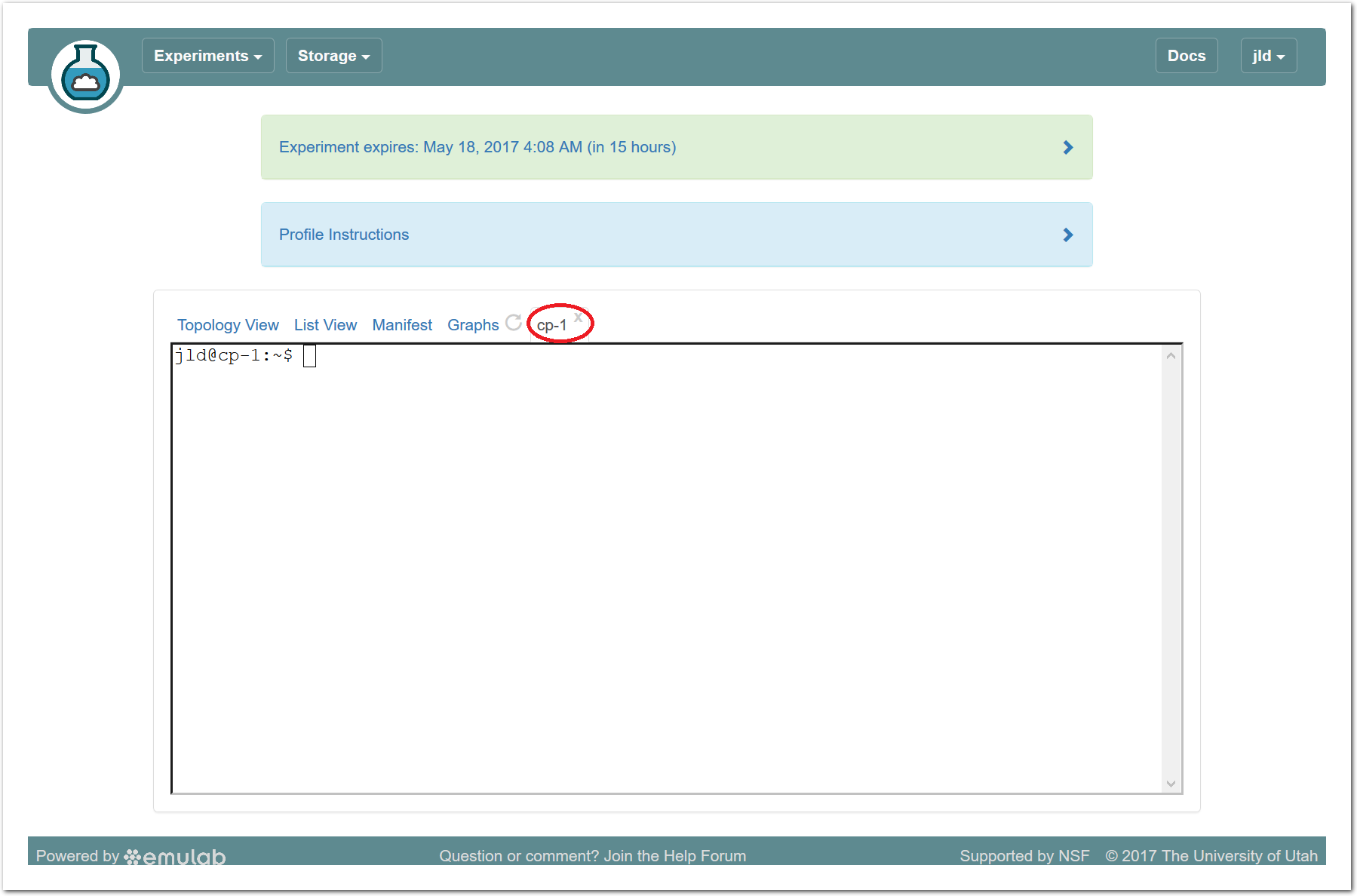
20.5.9 Serial Console
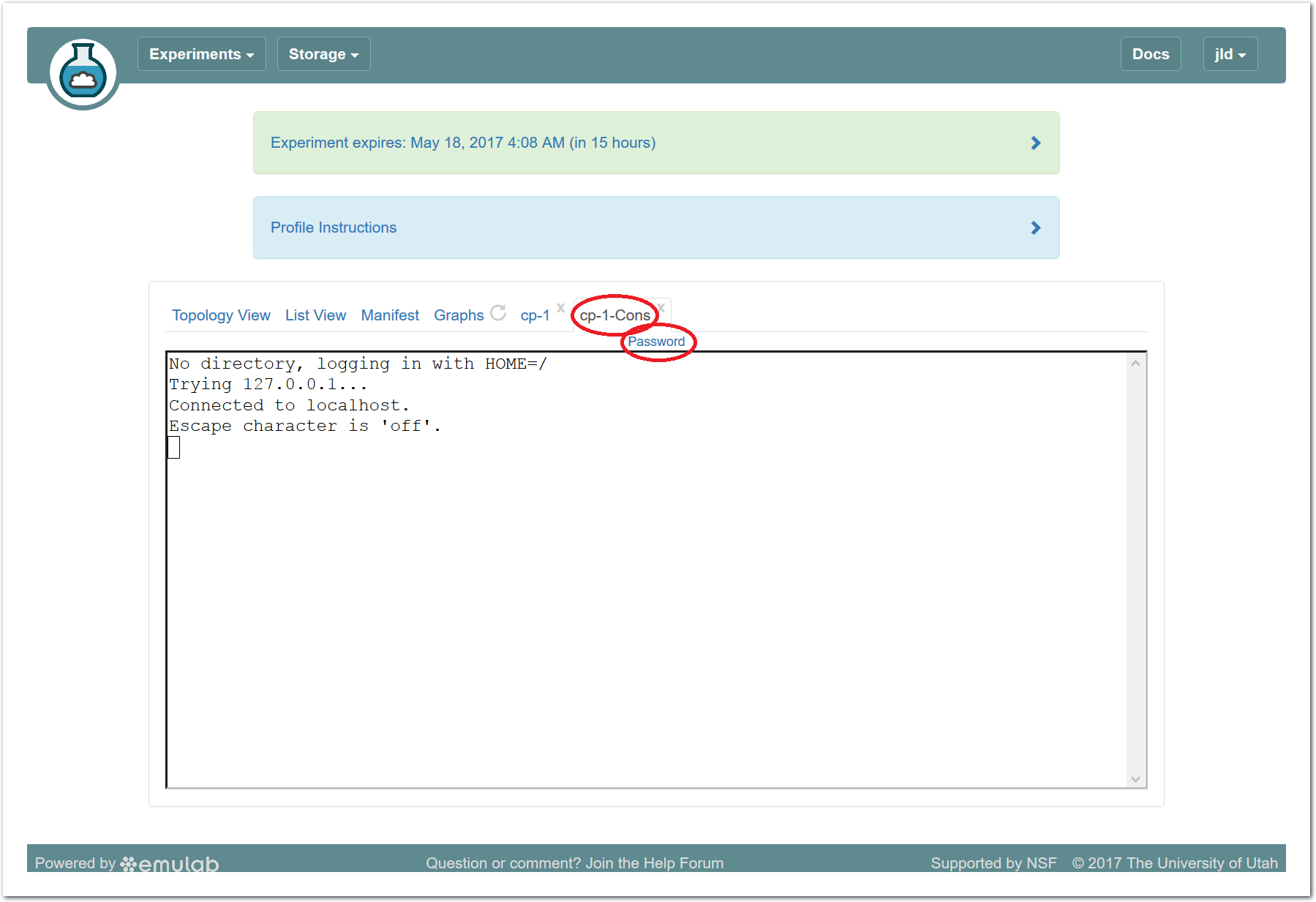
Powder provides serial console access for all nodes, which can be used in the event that normal IP or ssh access gets intentionally or unintentionally broken. Like the browser-based shell, it is launched through the access menu, and the same caveats listed above apply as well. In addition:
If you look at the console for a node that is already booted, the console may be blank due to a lack of activity; press enter several times to get a fresh login prompt.
If you need to log in, do so as root; your normal user account does not allow password login. There is a link above the console window that reveals the randomly-generated root password for your node. Note that this password changes frequently for security reasons.
20.6 Bringing up Instances in OpenStack
Now that you have your own copy of OpenStack running, you can use it just like you would any other OpenStack cloud, with the important property that you have full root access to every machine in the cloud and can modify them however you’d like. In this part of the tutorial, we’ll go through the process of bringing up a new VM instance in your cloud.
We’ll be doing all of the work in this section using the Horizon web GUI for OpenStack, but you could also ssh into the machines directly and use the command line interfaces or other APIs as well.
- Check to see if OpenStack is ready to log inAs mentioned earlier, this profile runs several scripts to complete the installation of OpenStack. These scripts do things such as finalize package installation, customize the installation for the specific set of hardware assigned to your experiment, import cloud images, and bring up the hypervisors on the compute node(s).If exploring the Powder experiment took you more than ten minutes, these scripts are probably done. You can be sure by checking that all nodes have completed their startup scripts (indicated by a checkmark on the Topology view); when this happens, the experiment state will also change from “Booting” to “Ready”
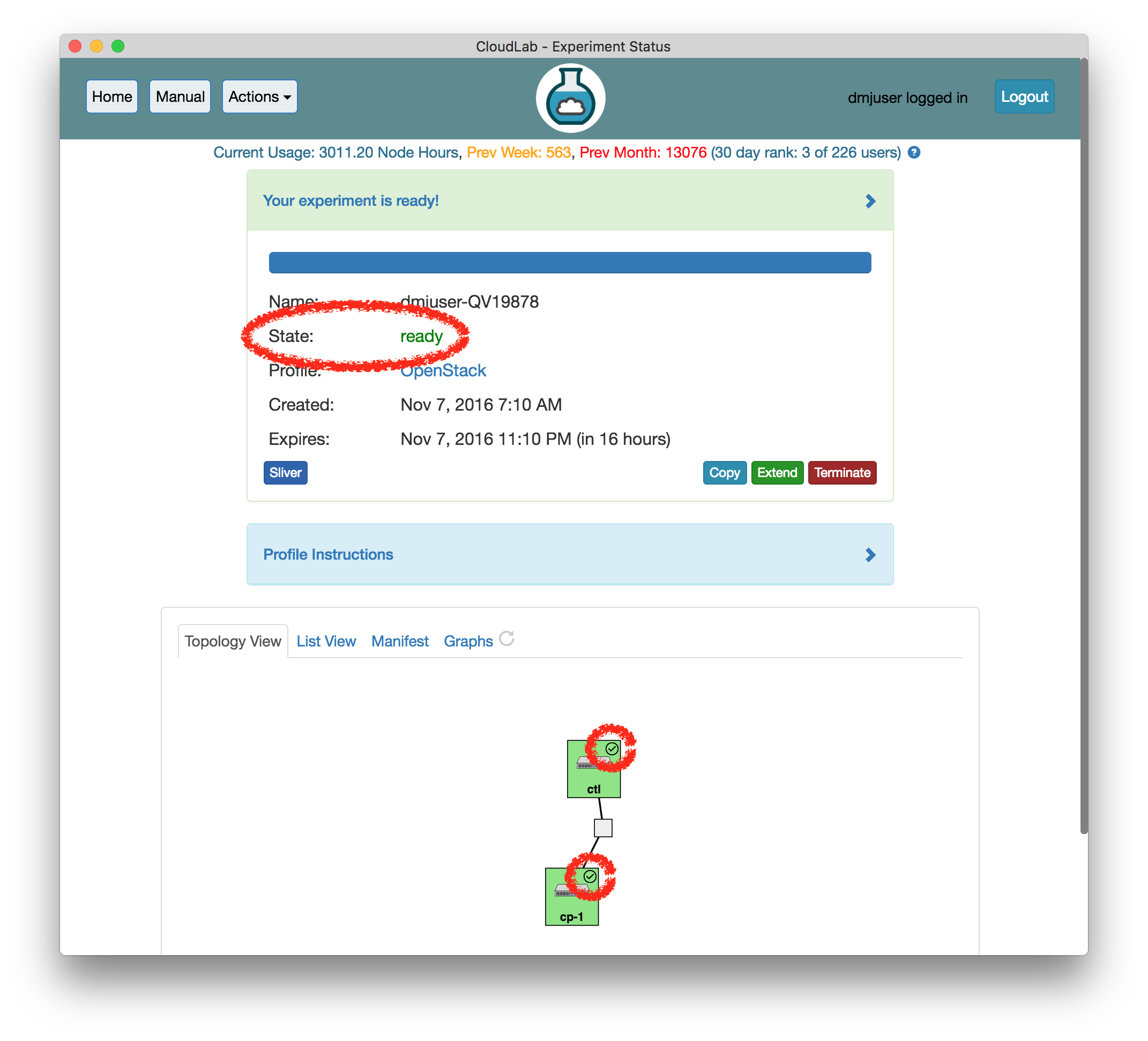 If you continue without verifying that the setup scripts are complete, be aware that you may see temporary errors from the OpenStack web interface. These errors, and the method for dealing with them, are generally noted in the text below.
If you continue without verifying that the setup scripts are complete, be aware that you may see temporary errors from the OpenStack web interface. These errors, and the method for dealing with them, are generally noted in the text below. - Visit the OpenStack Horizon web interfaceOn the status page for your experiment, in the “Instructions” panel (click to expand it if it’s collapsed), you’ll find a link to the web interface running on the ctl node. Open this link (we recommend opening it in a new tab, since you will still need information from the Powder web interface).
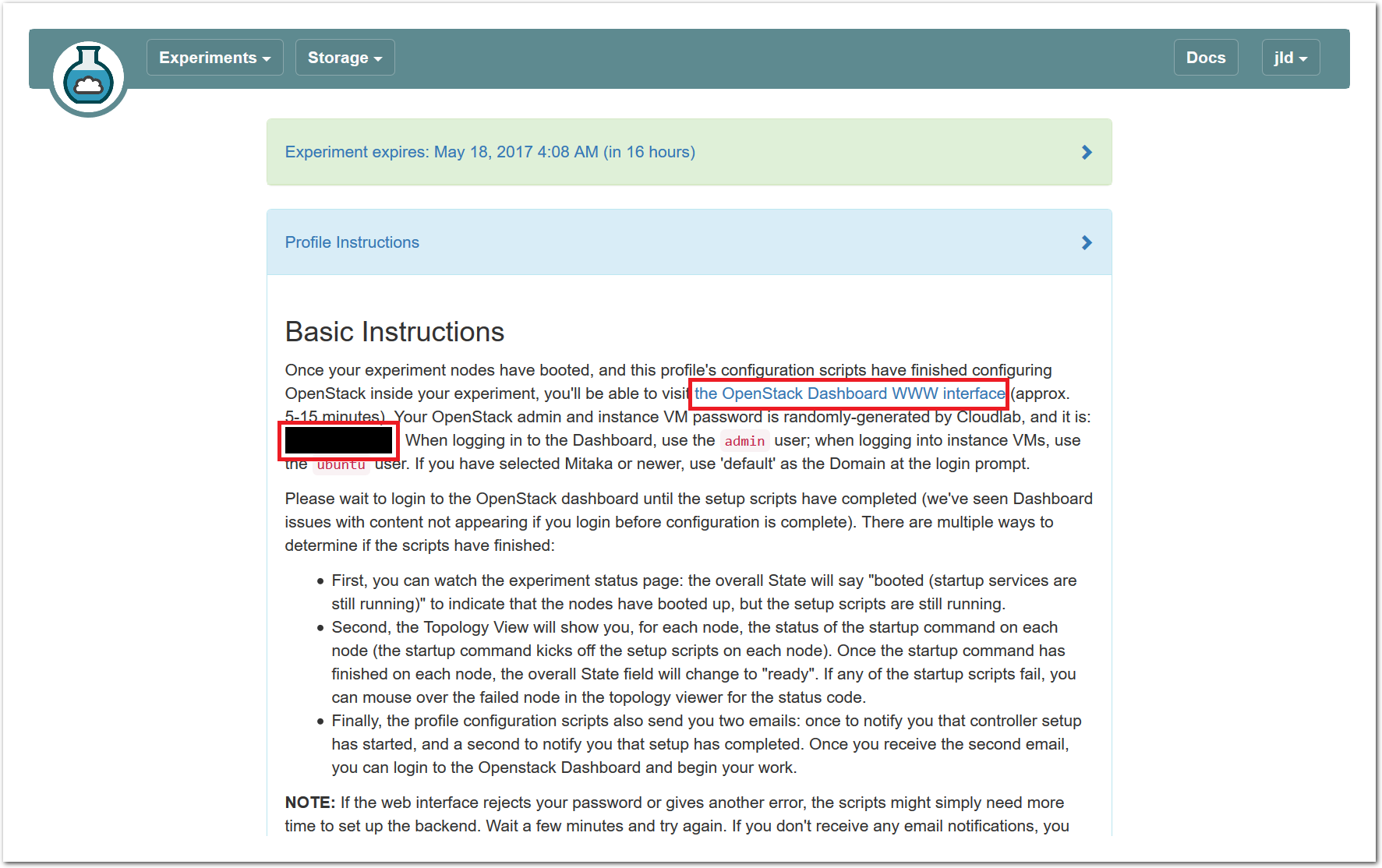
- Log in to the OpenStack web interfaceLog in using the username admin and the password shown in the instructions for the profile. Use the domain name default if prompted for a domain.
This profile generates a new (random) password for every experiment.
Important: if the web interface rejects your password, wait a few minutes and try again. If it gives you another type of error, you may need to wait a minute and reload the page to get login working properly.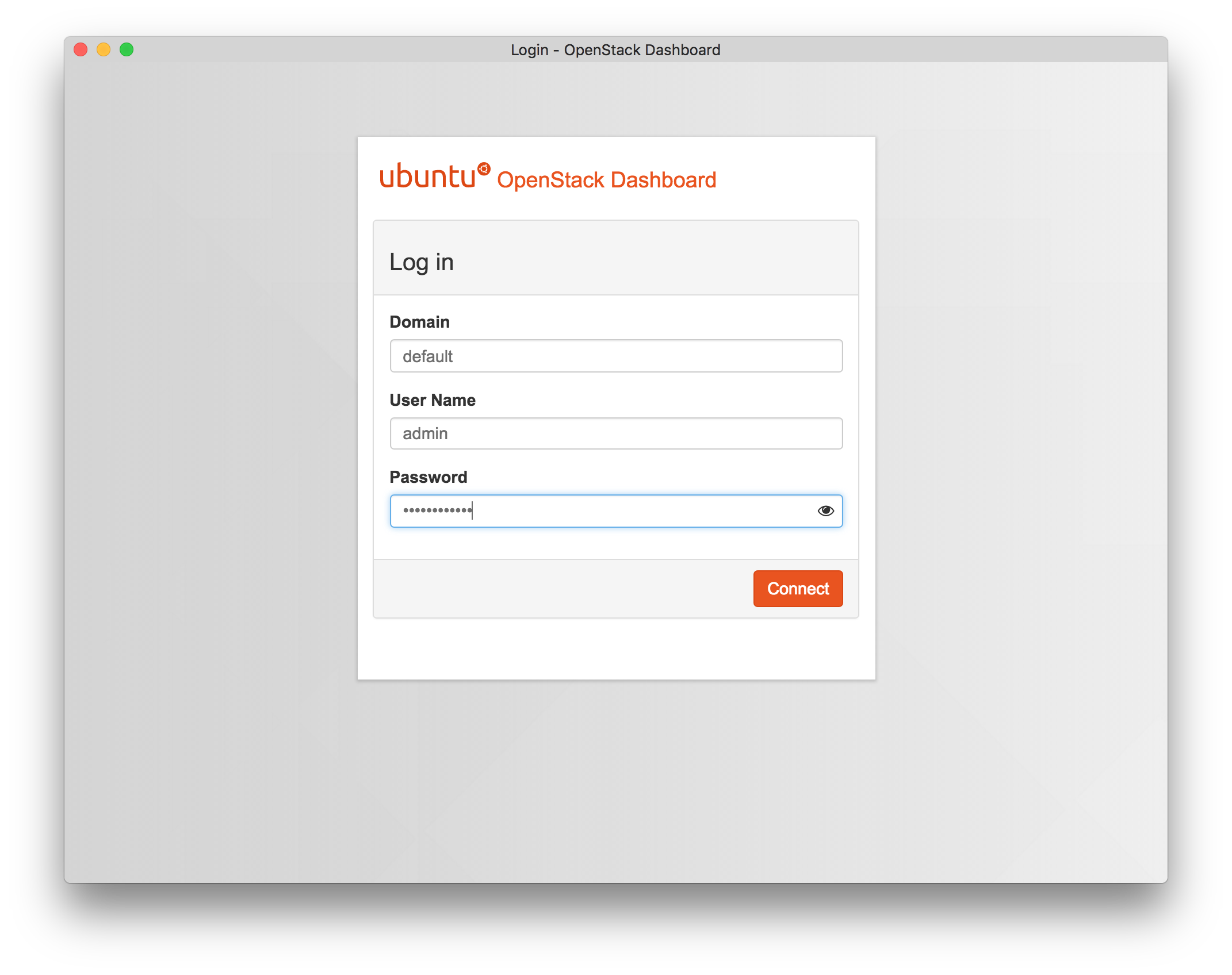
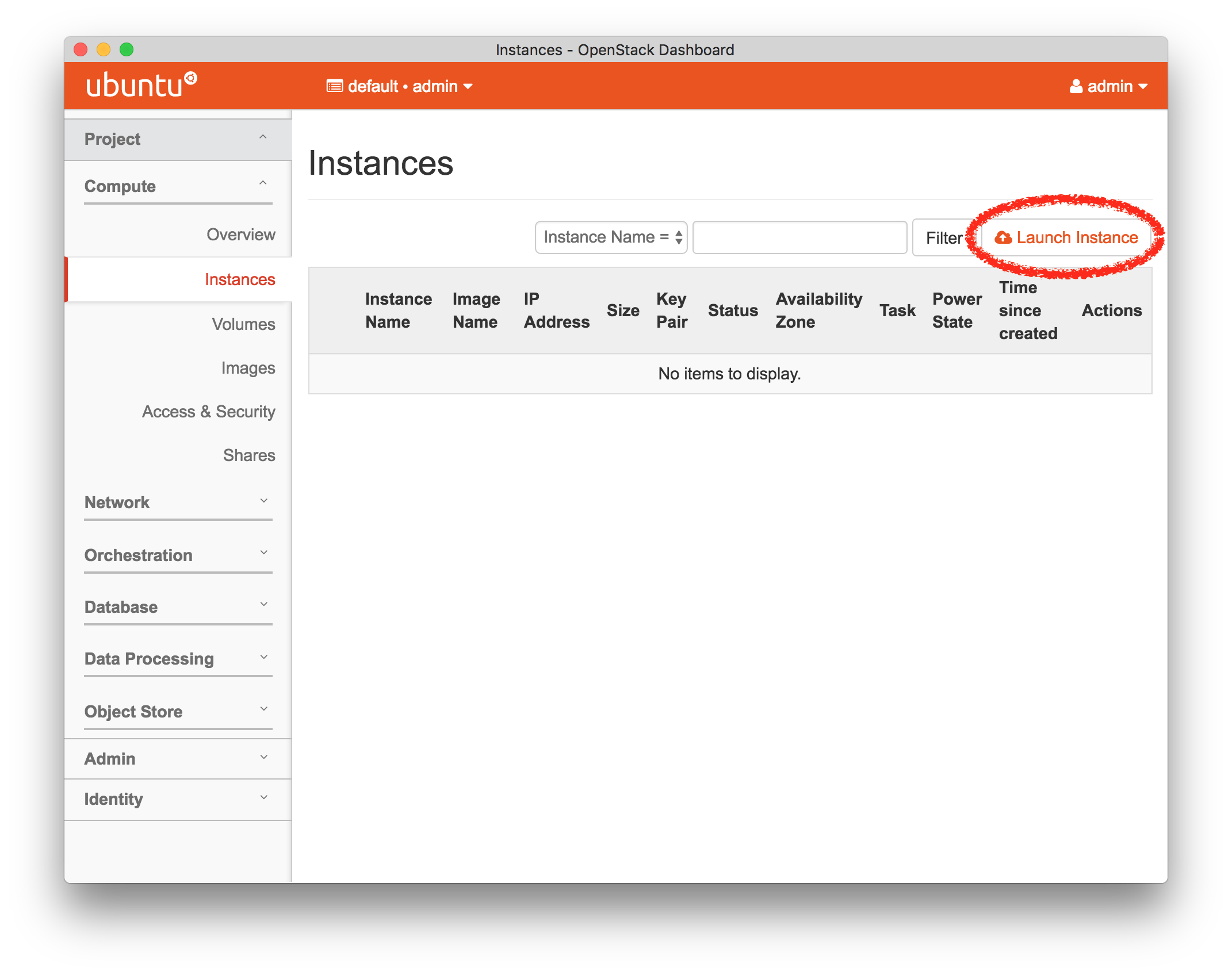
- Launch a new VM instanceClick the “Launch Instance” button on the “Instances” page of the web interface.
- Set Basic Settings For the InstanceThere a few settings you will need to make in order to launch your instance. These instructions are for the launch wizard in the OpenStack Mitaka, but the different release wizards are all similar in function and required information. Use the tabs in the column on the left of the launch wizard to add the required information (i.e., Details, Source, Flavor, Networks, and Key Pair), as shown in the following screenshots:
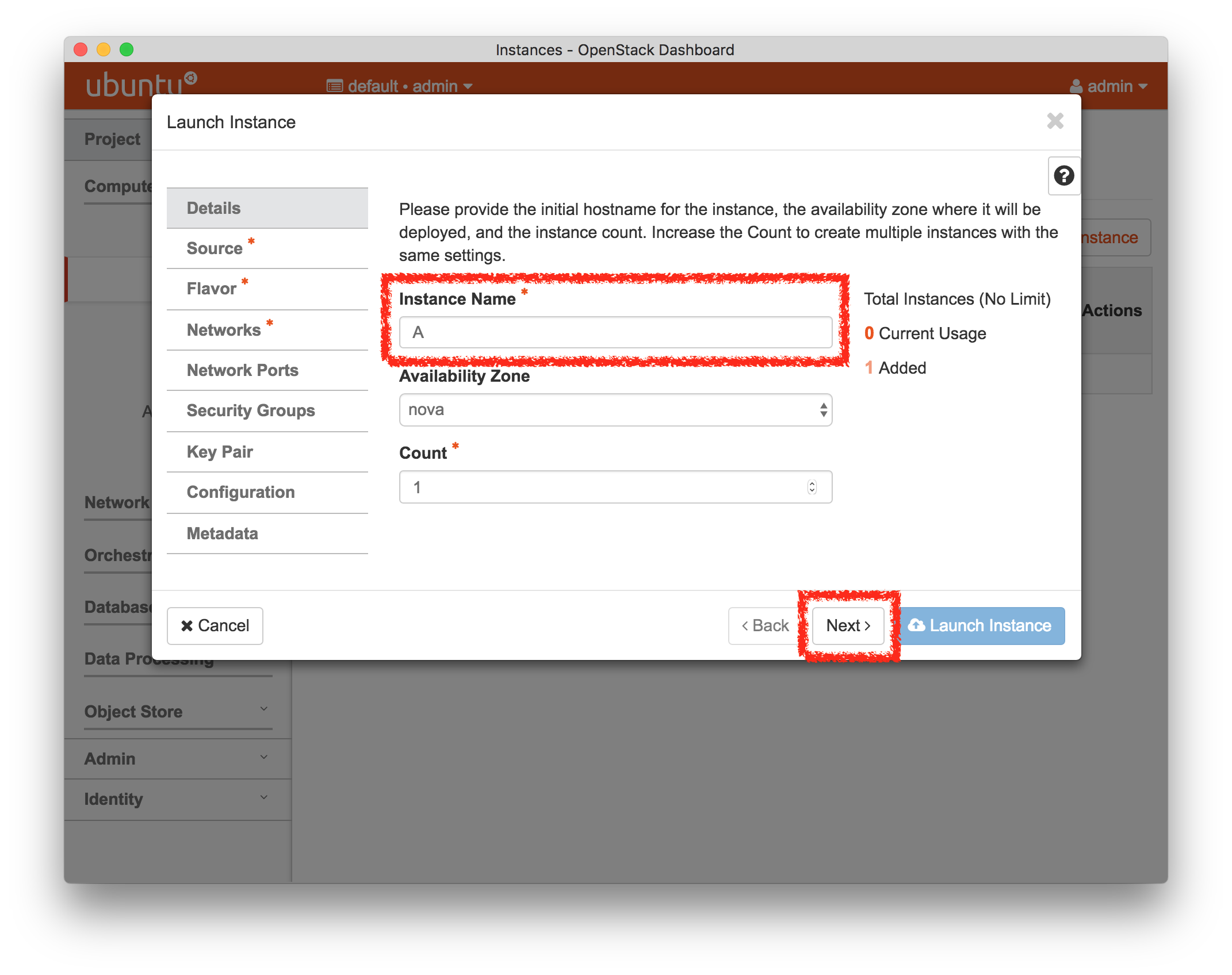
Pick any “Instance Name” you wish
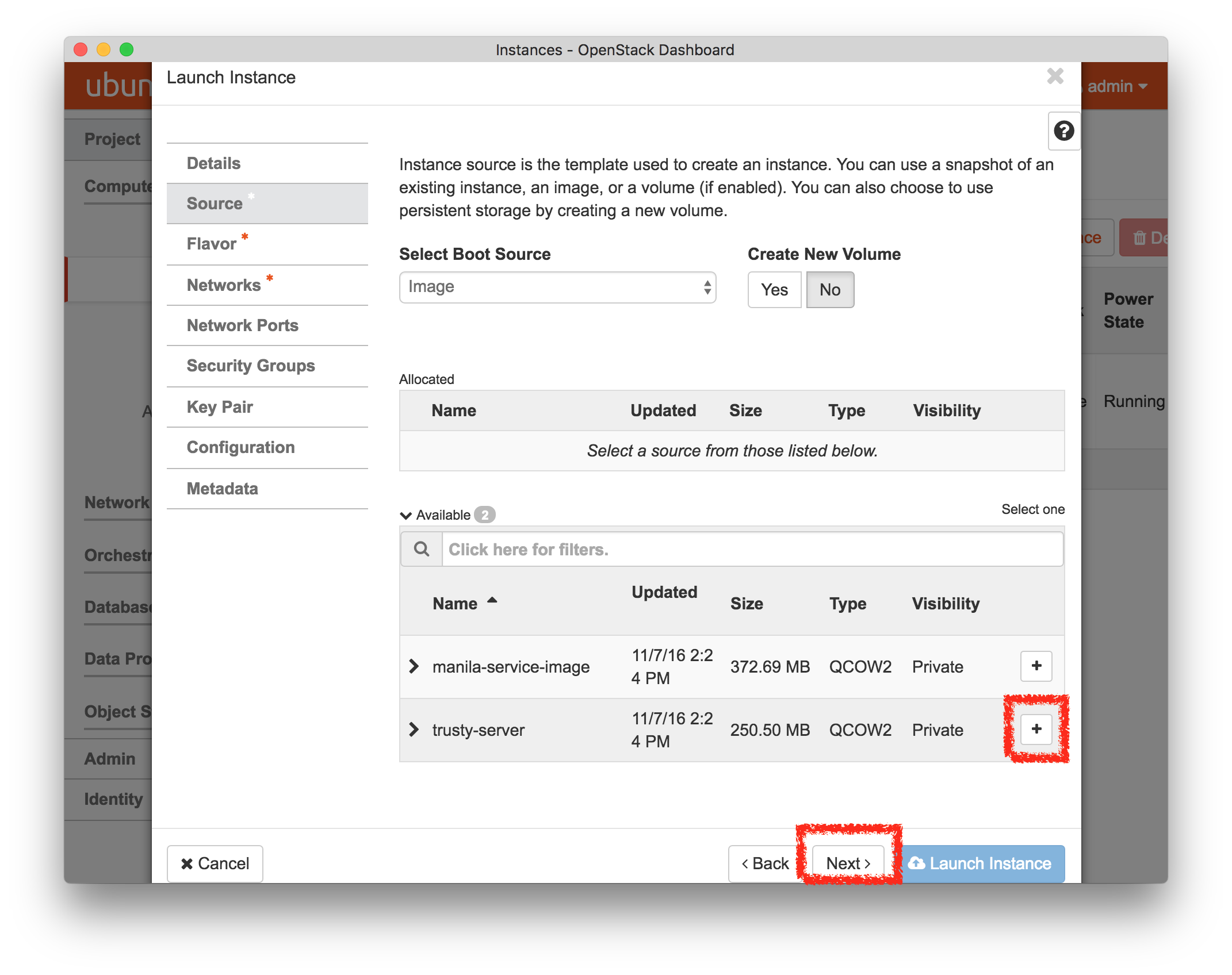
For the “Image Name”, select “trusty-server”
For the “Instance Boot Source”, select “Boot from image”
Important: If you do not see any available images, the image import script may not have finished yet; wait a few minutes, reload the page, and try again.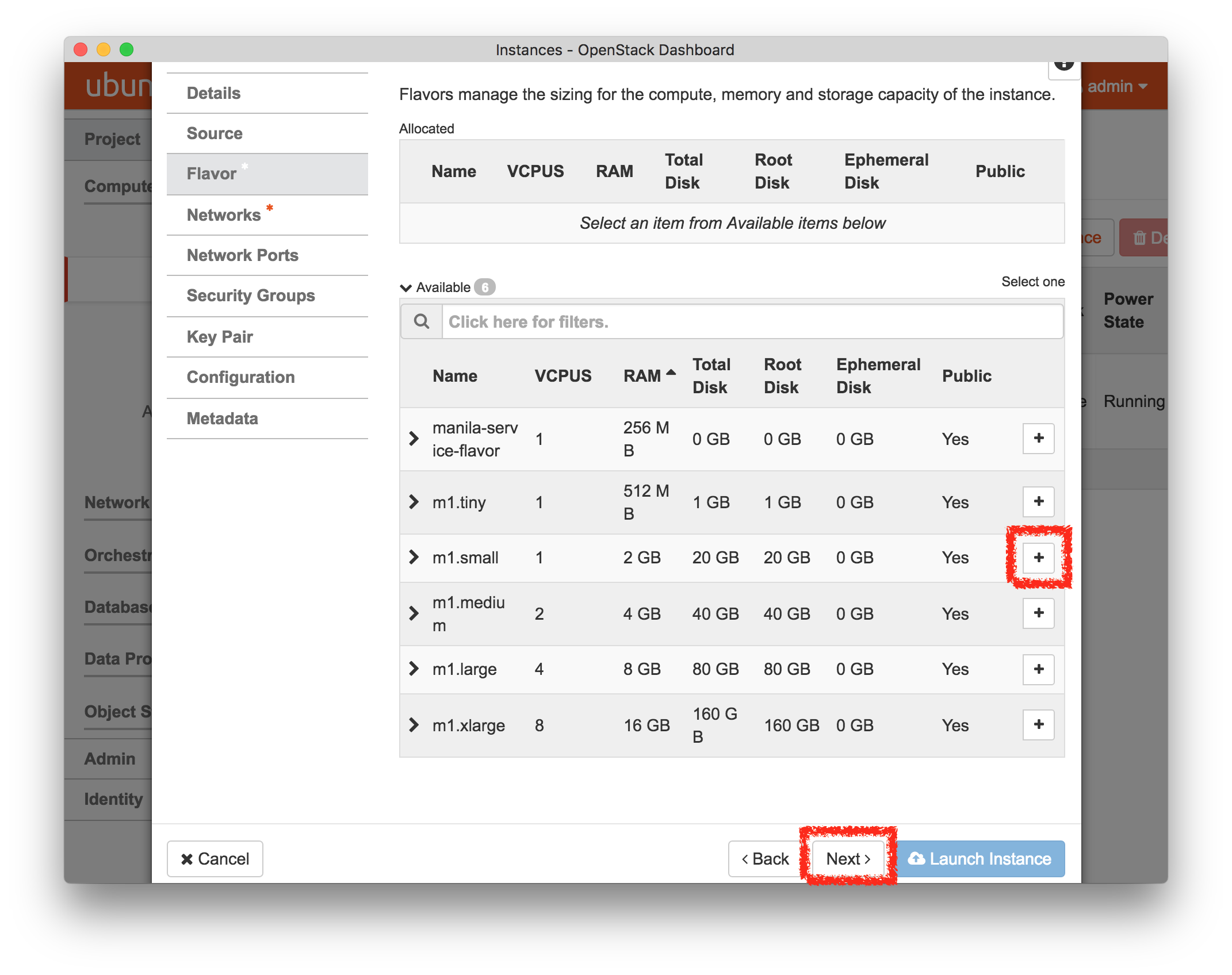
Set the “Flavor” to m1.small—
the disk for the default m1.tiny instance is too small for the image we will be using, and since we have only one compute node, we want to avoid using up too many of its resources.
- Add a Network to the InstanceIn order to be able to access your instance, you will need to give it a network. On the “Networking” tab, add the tun0-net to the list of selected networks by clicking the “+” button or dragging it up to the blue region. This will set up an internal tunneled connection within your cloud; later, we will assign a public IP address to it.
The tun0-net consists of EGRE tunnels on the Powder experiment network.
Important: If you are missing the Networking tab, you may have logged into the OpenStack web interface before all services were started. Unfortunately, reloading does not solve this, you will need to log out and back in.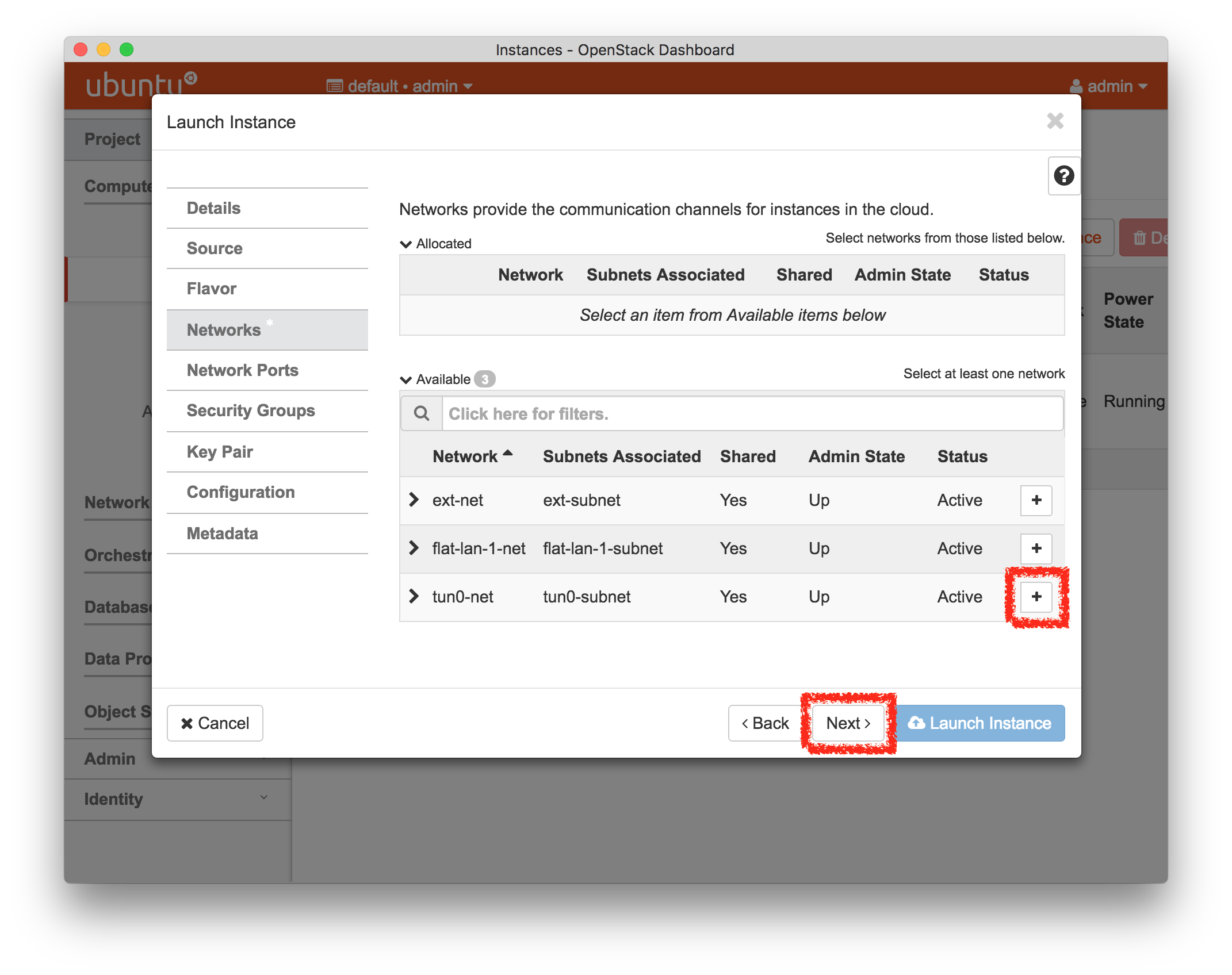
- Set an SSH KeypairOn the “Key Pair” tab (or “Access & Security” in previous versions), you will add an ssh keypair to log into your node. If you configured an ssh key in your GENI account, you should find it as one of the options in this list. You can filter the list by typing your Powder username, or a portion of it, into the filter box to reduce the size of the list. (By default, we load in public keys for all users in the project in which you created your experiment, for convenience – thus the list can be long.) If you don’t see your keypair, you can add a new one with the red button to the right of the list. Alternately, you can skip this step and use a password for login later.
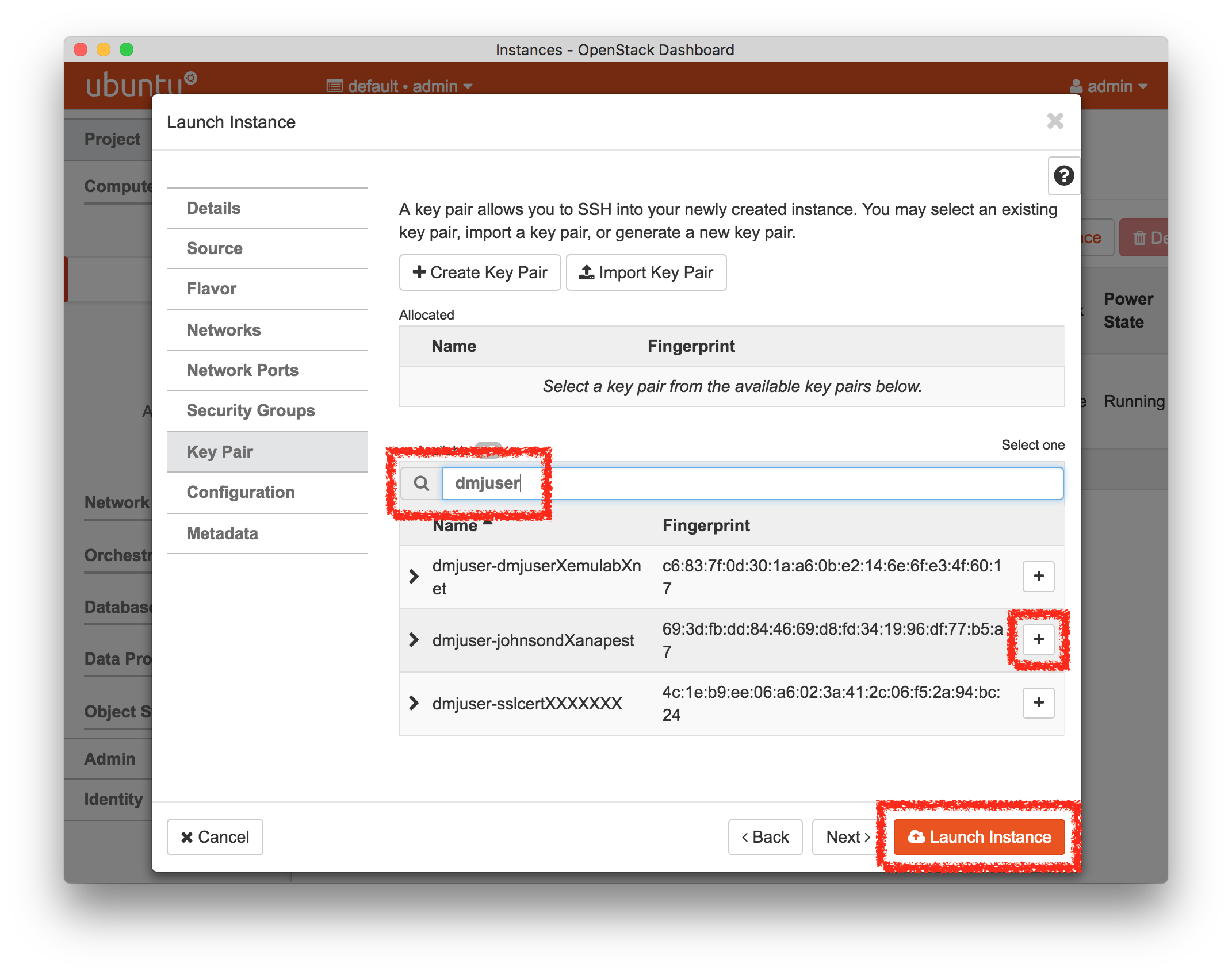
- Launch, and Wait For Your Instance to BootClick the “Launch” button on the “Key Pair” wizard page, and wait for the status on the instances page to show up as “Active”.
- Add a Public IP Address
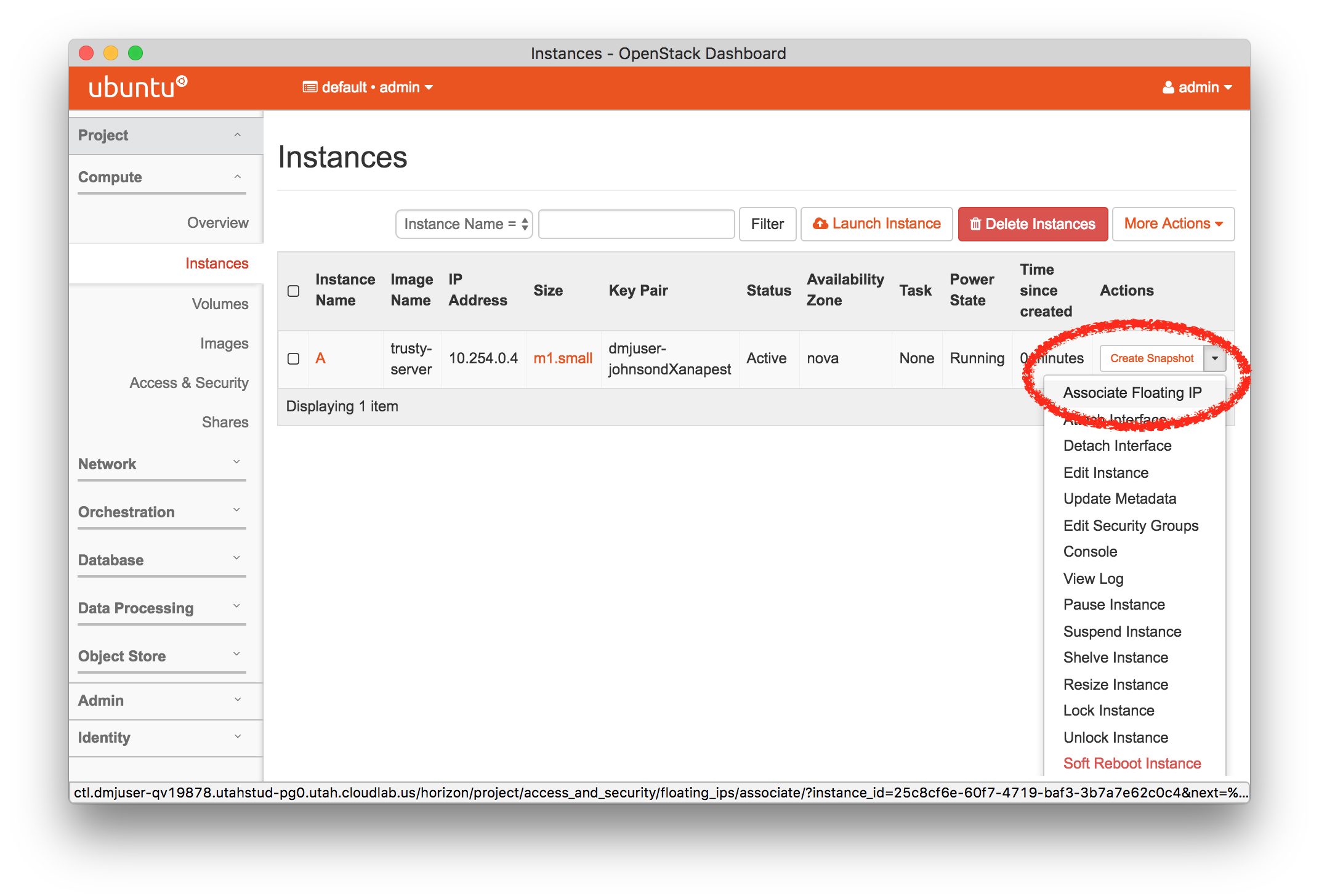 At this point, your instance is up, but it has no connection to the public Internet. From the menu on the right, select “Associate Floating IP”.
At this point, your instance is up, but it has no connection to the public Internet. From the menu on the right, select “Associate Floating IP”.Profiles may request to have public IP addresses allocated to them; this profile requests four (two of which are used by OpenStack itself.)
On the following screen, you will need to:Press the red button to set up a new IP address
Click the “Allocate IP” button—
this allocates a new address for you from the public pool available to your cloud. Click the “Associate” button—
this associates the newly-allocated address with this instance.
The public address is tunneled by the ctl (controller) node from the control network to the experiment network. (In older OpenStack profile versions, or depending the profile parameters specified to the current profile version, the public address may instead be tunneled by the nm (network manager) node, in a split controller/network manager OpenStack deployment.)
You will now see your instance’s public address on the “Instances” page, and should be able to ping this address from your laptop or desktop.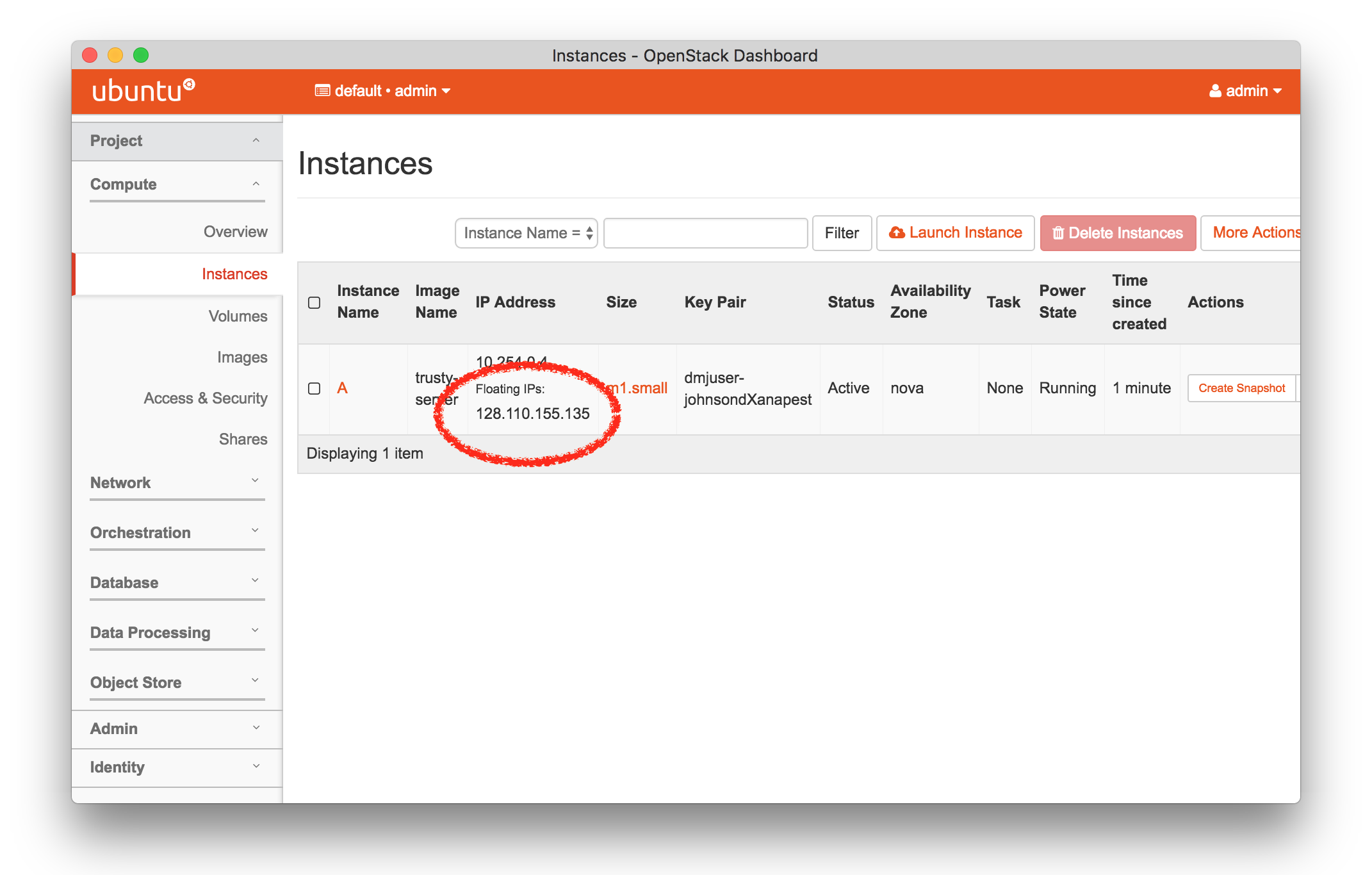
- Log in to Your InstanceYou can ssh to this IP address. Use the username ubuntu; if you provided a public key earlier, use your private ssh key to connect. If you did not set up an ssh key, use the same password you used to log in to the OpenStack web interface (shown in the profile instructions.) Run a few commands to check out the VM you have launched.
20.7 Administering OpenStack
Now that you’ve done some basic tasks in OpenStack, we’ll do a few things
that you would not be able to do as a user of someone else’s OpenStack
installation. These just scratch the surface—
20.7.1 Log Into The Control Nodes
If you want to watch what’s going on with your copy of OpenStack, you can use ssh to log into any of the hosts as described above in the List View or Web-based Shell sections. Don’t be shy about viewing or modifying things; no one else is using your cloud, and if you break this one, you can easily get another.
Some things to try:
Run ps -ef on the ctl to see the list of OpenStack services running
Run ifconfig on the ctl node (or the nm node, if your experiment has one), to see the various bridges and tunnels that have been brought to support the networking in your cloud
Run sudo virsh list --all on cp1 to see the VMs that are running
20.7.2 Reboot the Compute Node
Since you have this cloud to yourself, you can do things like reboot or re-image nodes whenever you wish. We’ll reboot the cp1 (compute) node and watch it through the serial console.
- Open the serial console for cp1On your experiment’s Powder status page, use the action menu as described in Actions to launch the console. Remember that you may have to click to focus the console window and hit enter a few times to see activity on the console.
- Reboot the nodeOn your experiment’s Powder status page, use the action menu as described in Actions to reboot cp1. Note that in the topology display, the box around cp1 will turn yellow while it is rebooting, then green again when it has booted.
- Watch the node boot on the consoleSwitch back to the console tab you opened earlier, and you should see the node starting its reboot process.
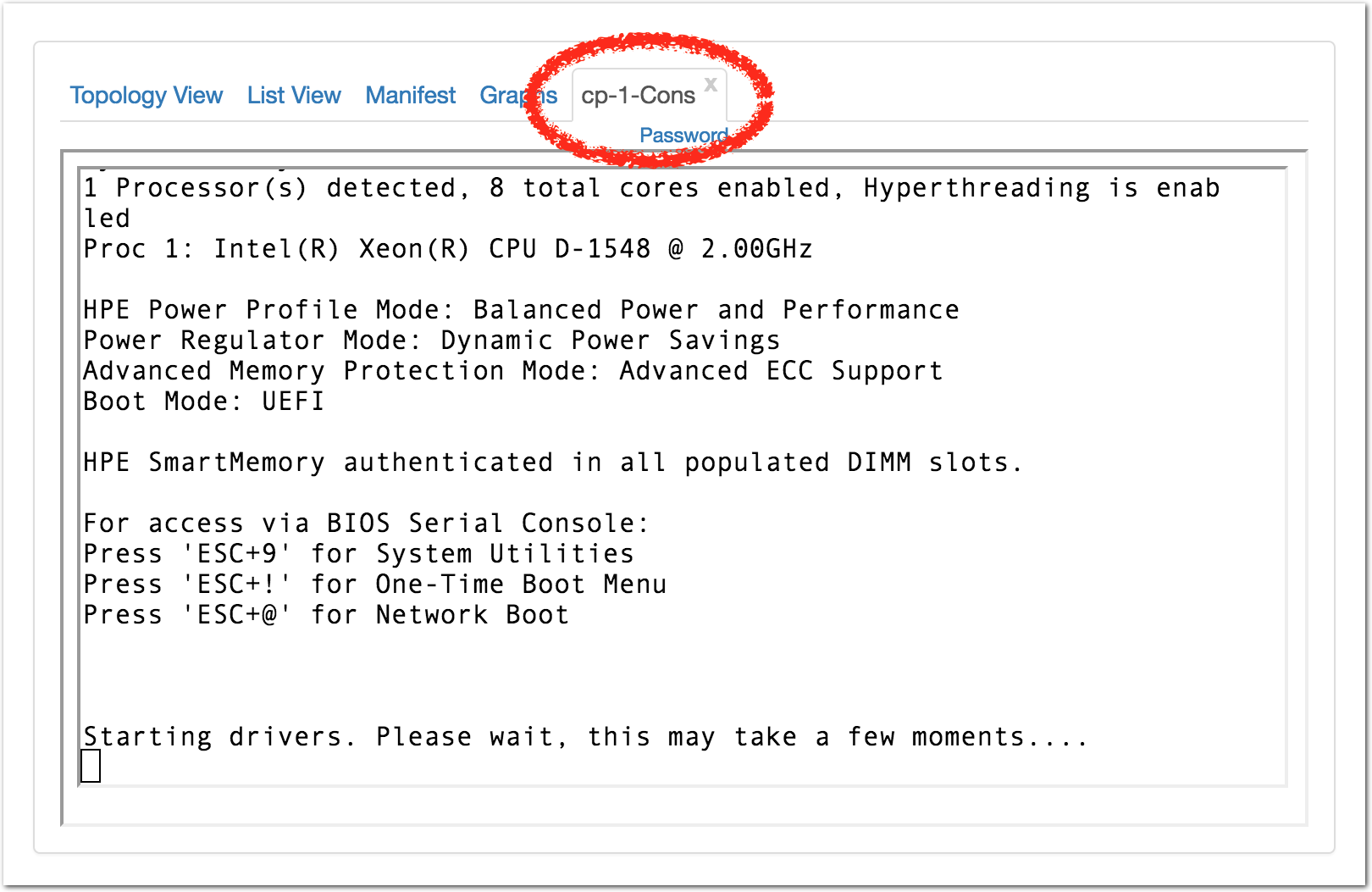
- Check the node status in OpenStackYou can also watch the node’s status from the OpenStack Horizon web interface. In Horizon, select “Hypervisors” under the “System” menu, and switch to the “Compute Host” tab.
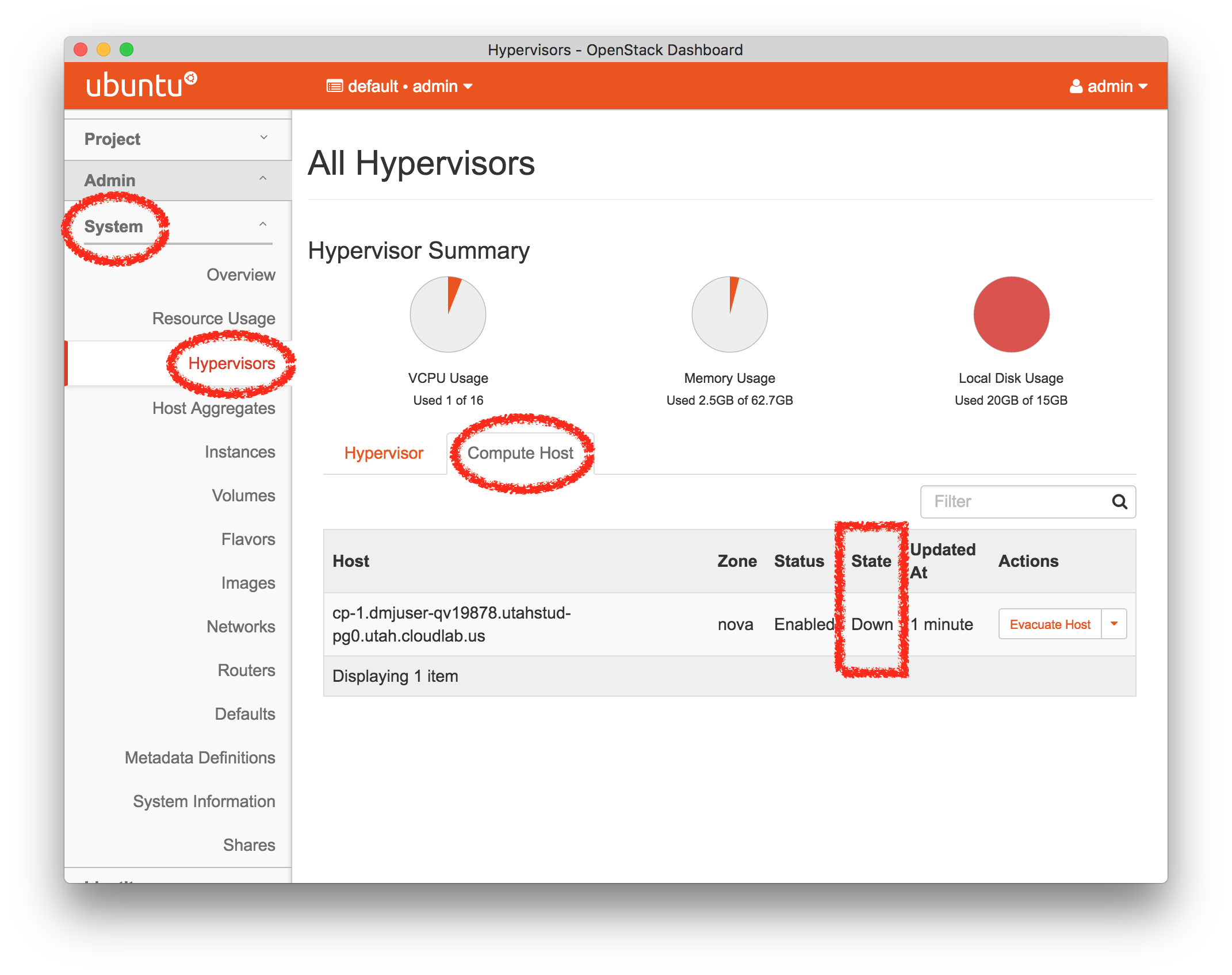 Note: This display can take a few minutes to notice that the node has gone down, and to notice when it comes back up. Your instances will not come back up automatically; you can bring them up with a “Hard Reboot” from the “Admin -> System ->Instances” page.
Note: This display can take a few minutes to notice that the node has gone down, and to notice when it comes back up. Your instances will not come back up automatically; you can bring them up with a “Hard Reboot” from the “Admin -> System ->Instances” page.
20.8 Terminating the Experiment
Resources that you hold in Powder are real, physical machines and are therefore limited and in high demand. When you are done, you should release them for use by other experimenters. Do this via the “Terminate” button on the Powder experiment status page.
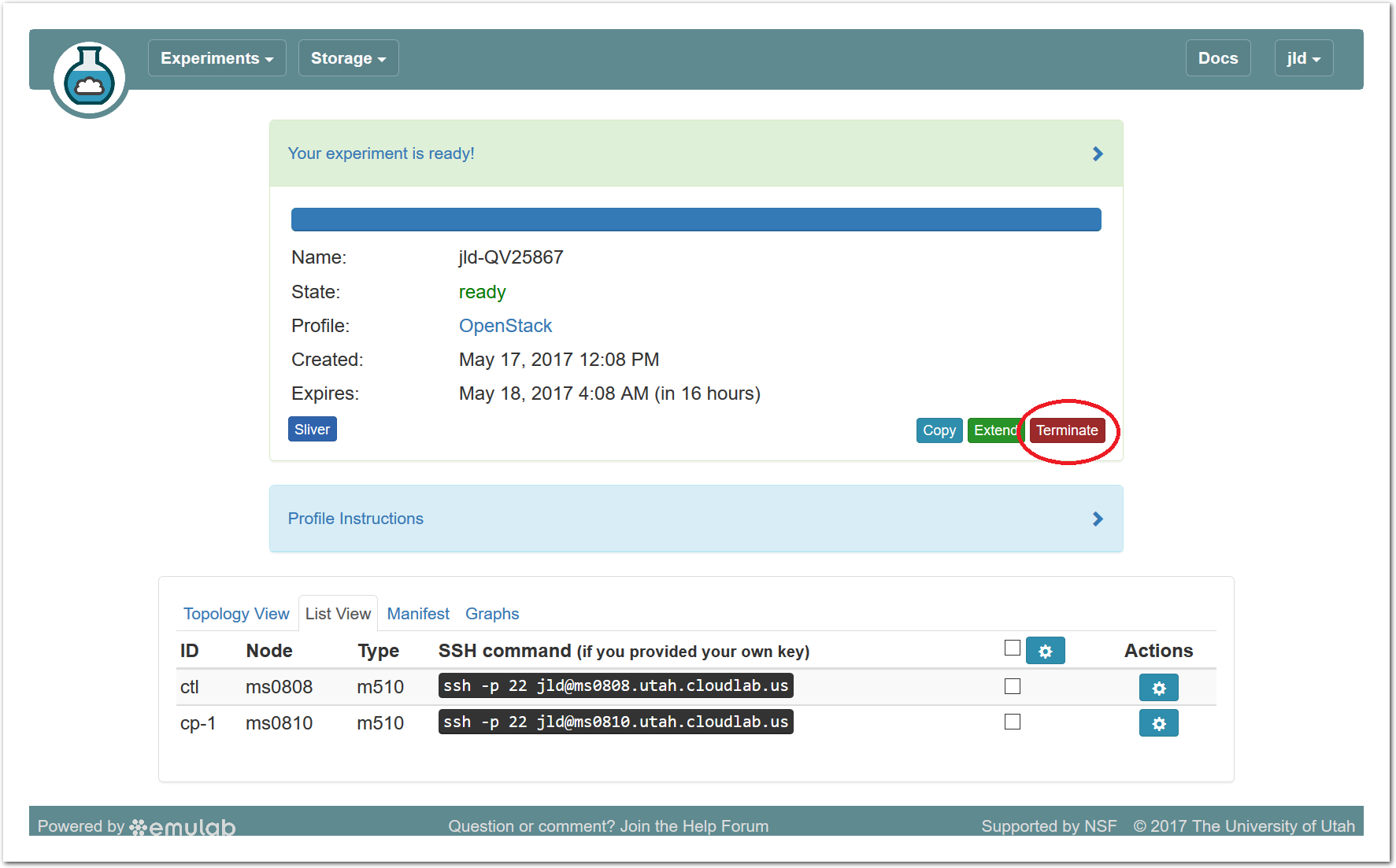
Note: When you terminate an experiment, all data on the nodes is lost, so make sure to copy off any data you may need before terminating.
If you were doing a real experiment, you might need to hold onto the nodes for longer than the default expiration time. You would request more time by using the “Extend” button the on the status page. You would need to provide a written justification for holding onto your resources for a longer period of time.
20.9 Taking Next Steps
Now that you’ve got a feel for for what Powder can do, there are several things you might try next:
Create a new project to continue working on Powder past this tutorial
Try out some profiles other than OpenStack (use the “Change Profile” button on the “Start Experiment” page)
Read more about the basic concepts in Powder
Try out different hardware
Learn how to make your own profiles