6 Basic Concepts
This chapter covers the basic concepts that you’ll need to understand in order to use Powder.
6.1 Profiles
A profile encapsulates everything needed to run an experiment. It consists of two main parts: a description of the resources (hardware, storage, radios, network, etc.) needed to run the experiment, and the software artifacts that run on those resources.
Resources on Powder are specified using Python-based geni-lib profile scripts. These scripts are executed by the Portal, and emit a flattened RSpec intermediate representation that is in turn used to manage them, and for instantiating experiments. There are several profile script examples on the example profiles page when logged into the Powder Portal.
The geni-lib profile script describes an entire topology: this includes the nodes (hosts) that the software will run on, the storage that they are attached to, radios and spectrum for transmission, and the wired network that connects them. The nodes may be virtual machines or physical servers. The geni-lib script can specify the properties of these nodes, such as how much RAM they should have, how many cores, etc., or can directly reference a specific class of hardware available in one of Powder’s clusters. The wired network topology can include point to point links, LANs, etc. The range(s) of spectrum to be used can also be specified. And in some cases of conducted RF, which devices have wired RF paths between them.
The primary way that software is associated with a profile is through
disk images. A disk image (often just called an
“image”) is a block-level snapshot of the contents of a real or virtual
disk—
Profiles come from two sources: some are provided by Powder itself; these tend to be standard installations of popular operating systems and software stacks. Profiles may also be provided by Powder’s users, as a way for communities to share research artifacts.
6.2 Experiments
See the chapter on repeatability for more information on repeatable experimentation in Powder.
An experiment is an instantiation of a profile. An experiment uses resources, virtual or physical, on one or more of the radio sites and compute clusters that Powder has access to. In most cases, the resources used by an experiment are devoted to the individual use of the user who instantiates the experiment. This means that no one else has an account, access to the filesystems, etc. In the case of experiments using solely physical machines, this also means strong performance isolation from all other Powder users.
Note that members of the project that the experiment belongs to typically also have full (root) access to the resources in that experiment.
Running experiments on Powder consume real resources, which are limited. We ask that you be careful about not holding on to experiments when you are not actively using them. If you are are holding on to experiments because getting your working environment set up takes time, consider creating a profile with one or more custom disk images that captures your environment.
The contents of local disks on nodes in an experiment are considered
ephemeral—
All experiments have an expiration time. By default, the expiration time is short (a few hours), but users can use the “Extend” button on the experiment page to request an extension. A request for an extension must be accompanied by a short description that explains the reason for requesting an extension, which will be reviewed by Powder staff. You will receive email a few hours before your experiment expires reminding you to copy your data off or request an extension.
6.2.1 Reserving Resources for Experiments
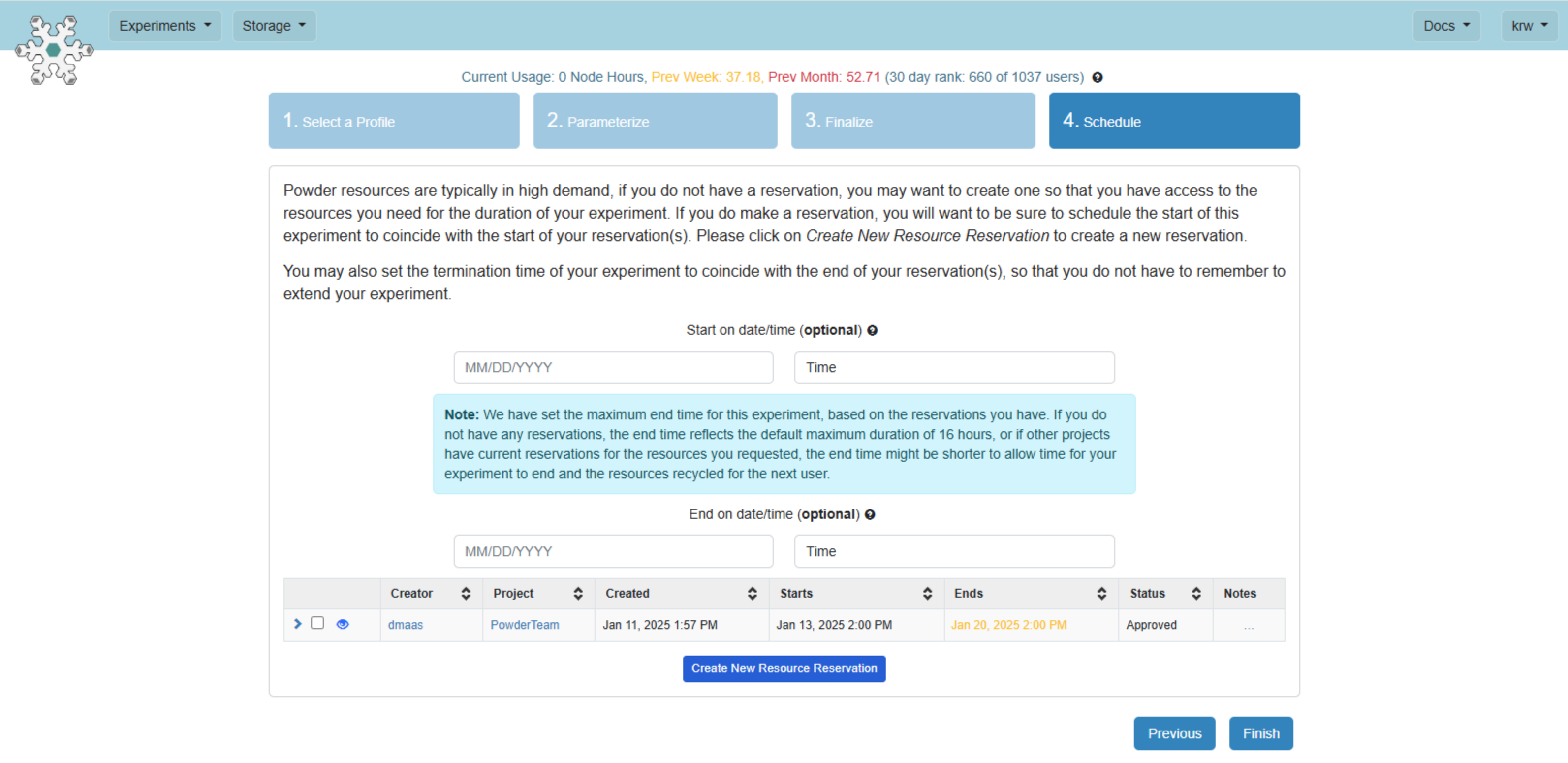
You are strongly advised to to create a reservation that covers the time period you wish to have resources available (similar to reserving a table at a restaurant). When instantiating an experiment from your profile, you can create a reservation during the "Scheduling" step. You can also select a matching reservation during this step (one that includes all the resources your experiment needs) by checking the box next to the list that appears near the bottom. This will cause your experiment’s duration to be set to the time window of the reservation. If this puts the start time in the future, your experiment will be scheduled to start at that later date and time. If the reservation has already started, the schedule step will leave the start time blank to instruct the testbed framework to start it immediately upon clicking "Finish".
6.2.2 Extending Experiments
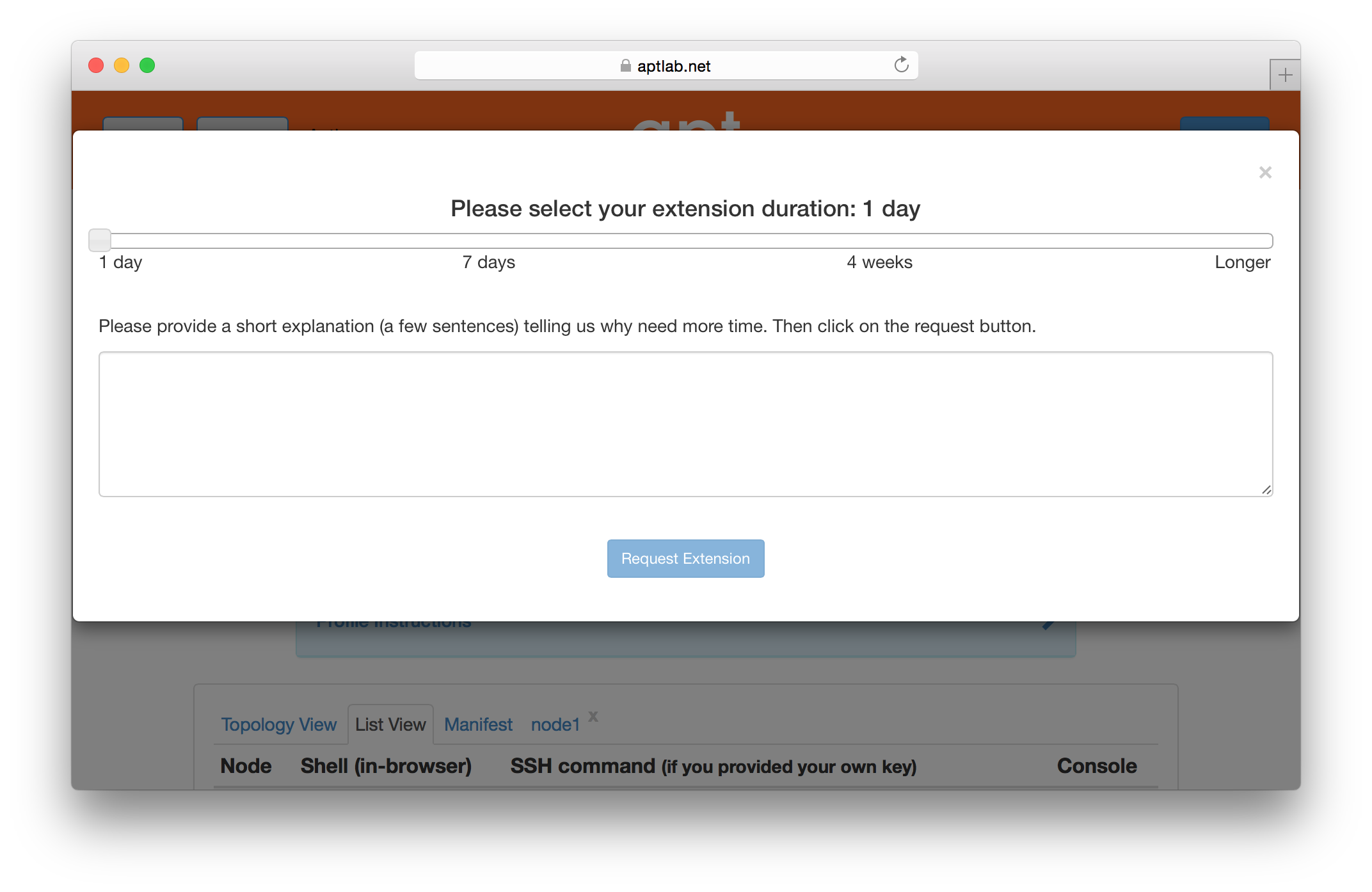
If you need more time to run an experiment, you may use the “Extend” button on the experiment’s page. You will be presented with a dialog that allows you to select how much longer you need the experiment. Longer time periods require more extensive appoval processes. Short extensions are auto-approved, while longer ones require the intervention of Powder staff .
6.3 Projects
Users are grouped into projects. A project is, roughly speaking, a group of people working together on a common research or educational goal. This may be people in a particular research lab, a distributed set of collaborators, instructors and students in a class, etc.
A project is headed by a project leader. We require that project leaders be faculty, senior research staff, or others in an authoritative position. This is because we trust the project leader to approve other members into the project, ultimately making them responsible for the conduct of the users they approve. If Powder staff have questions about a project’s activities, its use of resources, etc., these questions will be directed to the project leader. Some project leaders run a lot of experiments themselves, while some choose to approve accounts for others in the project, who run most of the experiments. Either style works just fine in Powder.
Permissions for some operations/resources depend on the project that they belong to. Profile access, use of specific compute node types, rights to use outdoor radios, and image usage are examples of resources with permissions that are moderated by project membership.
6.4 Physical Resources
Users of Powder may get exclusive, low-level (root) control over physical machines. When allocated this way, no layers of virtualization or indirection get in the way of the way of performance, and users can be sure that no other users have access to the machines at the same time. This is an ideal situation for repeatable research.
Radio devices on Powder are similarly provided without virtualization, and full low-level access for changing firmware and settings.
Physical machines are re-imaged between users, so you can be sure that your physical machines don’t have any state left around from the previous user. You can find descriptions of the hardware in Powder’s clusters in the hardware chapter.
6.5 Virtual Machines
To support experiments that must scale to large numbers of nodes, Powder provides virtual nodes. A Powder virtual node is a virtual machine running on top of a regular operating system. If an experiment’s per-node CPU, memory and network requirements are modest, the use of virtual nodes allows an experiment to scale to a total node size that is a factor of tens or hundreds times as many nodes as there are available physical machines in Powder. Virtual nodes are also useful for prototyping experiments and debugging code without tying up significant amounts of physical resources.
Powder virtual nodes are based on the Xen hypervisor. With some limitations, virtual nodes can act in any role that a normal Powder node can: edge node, router, traffic generator, etc. You can run startup commands, remotely login over ssh, run software as root, use common networking tools like tcpdump or traceroute, modify routing tables, capture and load custom images, and reboot. You can construct arbitrary topologies of links and LANs mixing virtual and real nodes.
Virtual nodes in Powder are hosted on either dedicated or shared physical machines. In dedicated mode, you may login to the physical machines hosting your VMs; in shared mode, no one else has access to your VMs, but there are other users on the same hardware whose activities may affect the performance of your VMs.
To learn how to allocate and configure virtual nodes, see the the advanced topics section.